Tessl Skill Evaluation Framework: Treating Agent Skills as Production Software
Tessl Skill Evaluation Framework: Treating Agent Skills as Production Software
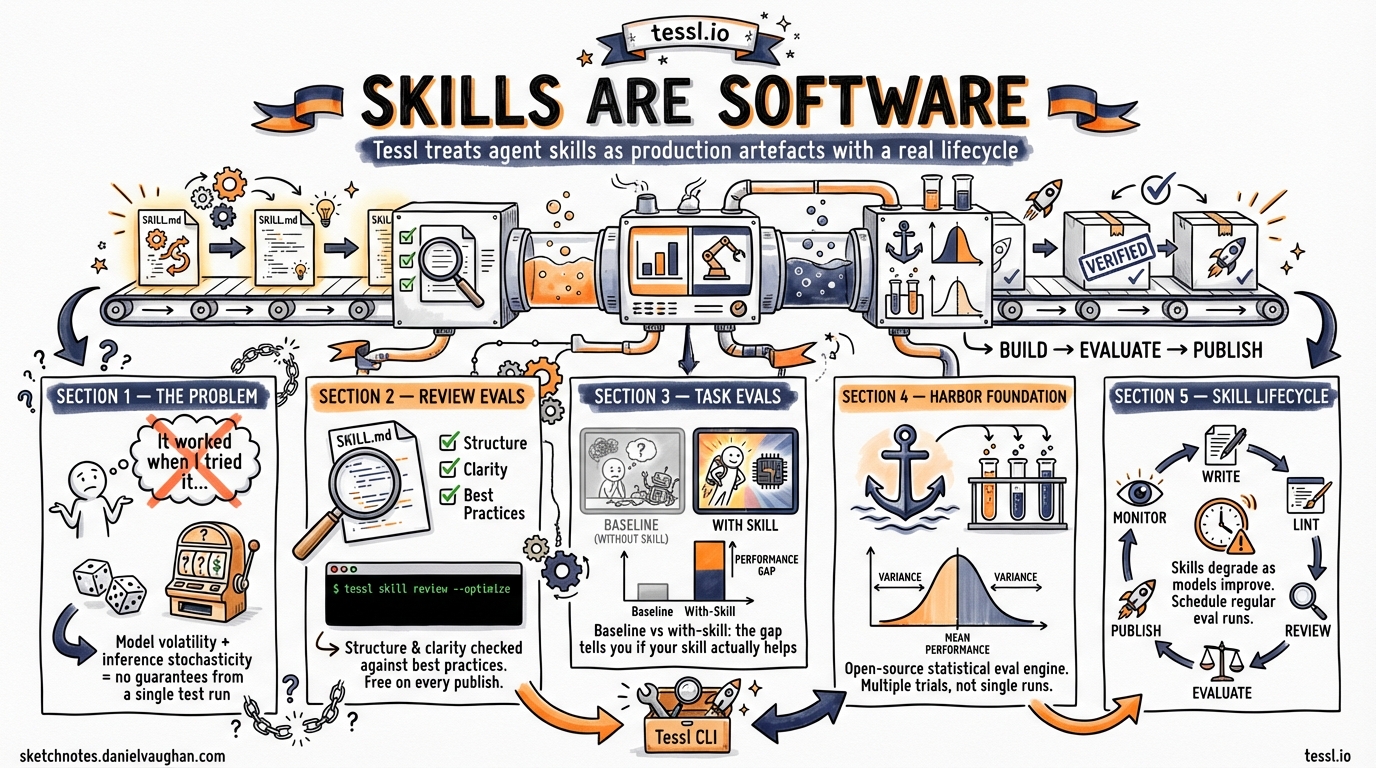
You have written a skill for your coding agent. It looks right. It seems to work when you try it. But does it actually change the agent’s behaviour, or would the base model have done just as well without it? Tessl exists to answer that question with data rather than intuition.
What Tessl Is
Tessl is an agent enablement platform that treats skills, the structured instruction files that guide AI coding agents, as first-class software artefacts with a proper lifecycle1. Where most developers write a SKILL.md, copy it into their repository, and hope for the best, Tessl provides the infrastructure to build, evaluate, distribute, and maintain skills over time.
The platform has three layers:
- A CLI (
npm i -g @tessl/cli) for creating, linting, evaluating, and publishing skills2. - A registry containing over 2,000 evaluated skills, searchable and installable like npm packages1.
- An evaluation engine that measures whether a skill genuinely improves agent performance on real tasks.
Tessl supports multiple agents out of the box. Running tessl init lets you configure for Claude Code, Cursor, Gemini, Codex CLI, OpenClaw, Copilot, or any agent that reads the Agent Skills specification2.
The Evaluation Problem
Traditional software testing assumes determinism: the same input produces the same output. AI agents break this assumption in two ways3:
- Model volatility. Providers continuously release new model versions that change agent behaviour without any configuration change on your part.
- Inference stochasticity. Even identical tasks produce varying results due to temperature, sampling, and context window variations.
‘It worked when I tried it’ provides almost no validation signal for non-deterministic systems3. A skill that appears to help today might become redundant after a model update, or worse, actively contradict the model’s improved capabilities. You need a repeatable, statistical evaluation methodology.
Two Evaluation Methods
Tessl provides two complementary approaches to skill evaluation4.
Review Evaluations
A review evaluation tests the structure of your skill against Anthropic’s best practices for writing agent instructions. It checks whether your skill is well-formed, whether models and agents can parse it correctly, and whether the instructions are clear enough to influence behaviour reliably4.
Run a review with:
tessl skill review ./my-skill
The review score runs on every publish, before anyone in the registry sees your skill. Think of it as a linter for instruction quality.
For iterative improvement, add the --optimize flag:
tessl skill review ./my-skill --optimize --max-iterations 5
This runs up to five improvement loops, each refining the skill file against the specification2.
Task Evaluations
Task evaluations measure whether a skill changes agent behaviour in practice. The methodology is straightforward5:
- Tessl analyses your skill and generates evaluation scenarios automatically.
- For each scenario, the agent attempts the task without the skill (baseline run).
- The same agent attempts the same task with the skill injected.
- Tessl compares the two results and scores the gap.
The gap between baseline and with-skill scores tells you what you need to know5:
| Gap | Interpretation |
|---|---|
| Large positive | The skill effectively steers agent behaviour |
| Small positive | The skill helps, but the agent already performs the task reasonably well |
| Near zero | The skill has no measurable effect |
| Negative | The skill’s instructions may contradict the model’s training |
Scenario-Based Evaluation in Practice
Scenarios live in an evals/ directory alongside your skill6:
my-skill/
SKILL.md
tile.json
evals/
instructions.json
scenario-1/
task.md
criteria.json
capability.txt
scenario-2/
task.md
criteria.json
capability.txt
summary.json
Each scenario has three files6:
- task.md contains the task brief presented to the agent, potentially including sample data.
- capability.txt declares which skill capability the scenario tests.
- criteria.json defines the scoring rubric, the specific metrics that determine success.
You can generate scenarios in three ways:
# Automatic generation from your skill
tessl scenario generate ./my-skill --count=5
# From specific git commits (for codebase-aware scenarios)
tessl scenario generate ./my-skill --commits abc123,def456
# From pull requests
tessl scenario generate ./my-skill --prs 42,43
Then run the evaluation:
tessl eval run ./my-skill --agent claude:claude-sonnet-4-6 --label "v2 comparison"
View results with:
tessl eval view --last
tessl eval compare --breakdown
Harbor: The Open-Source Foundation
Underneath Tessl’s evaluation engine sits Harbor, an open-source framework for evaluating AI agents in containerised environments3. Harbor emerged from Terminal-Bench, the collaborative benchmark developed by Laude Institute and Stanford researchers.
Harbor uses statistical evaluation rather than binary pass/fail3:
- Runs tasks multiple times across configurations.
- Computes pass rates over N trials instead of relying on single runs.
- Reports mean performance and variance.
- Enables hypothesis testing for configuration changes.
This statistical approach is essential because a single evaluation run tells you almost nothing about a non-deterministic system. You need repeated trials to separate genuine skill impact from random variation.
Harbor serves three functions within the broader ecosystem3:
- Evaluation gates. Pre-deployment validation, similar to CI/CD testing for traditional software.
- Regression detection. Identifying whether prompt or configuration changes improve or degrade performance over time.
- Training signals. Enabling Reinforcement Learning from Verifiable Rewards, where successful task trajectories feed back into model improvement.
Skill Creator V2: The Authoring Side
While Tessl focuses on the evaluation and distribution lifecycle, Anthropic’s Skill Creator V2 provides complementary tooling for the authoring phase7. The two systems address different parts of the same problem.
Skill Creator V2 introduces several capabilities relevant to evaluation7:
Parallel sub-agent execution. Independent agents execute evaluations in parallel, each operating in isolated contexts with separate token and timing metrics. This eliminates context bleeding between test runs.
Comparator agents. A/B comparison functionality tests two skill versions, or skill versus baseline, using comparator agents that evaluate outputs without knowing which variant they are assessing. This ensures unbiased quality judgement7.
Benchmark mode. A standardised assessment tracks three metrics: evaluation pass rate, elapsed execution time, and token consumption. Teams can deploy benchmarks after model updates or during iterative skill refinement.
In one documented example, the baseline skill scored 81 on evaluation metrics while the improved version achieved 97.5, a 15.7 per cent overall improvement across test cases8. Two of four evaluations showed measurable gains while two tied with the baseline.
Description optimisation. Skill Creator V2 analyses skill descriptions against sample prompts and suggests refinements to reduce both false positives and false negatives in skill triggering. Testing across six public document-creation skills showed triggering improvements in five of them7.
The Cost Question
A recurring concern in the community is whether the token cost of evaluation is justified. Running parallel executions with comparator agents can cost between $12 and $15 per evaluation cycle, depending on the model and number of scenarios8.
The answer depends on what the skill does:
| Skill type | Evaluation spend | Justification |
|---|---|---|
| Personal formatting helper | Probably not worth it | The skill is cheap to rewrite if it breaks |
| Team-shared code review skill | Worth a single evaluation run | Affects multiple developers daily |
| Enterprise workflow automation | Worth regular scheduled evaluation | A Jira-to-deployment pipeline that saves 100 engineer-hours per month easily justifies $15 in evaluation tokens |
| Registry-published skill | Essential | You owe it to consumers to prove the skill works |
Tessl’s review evaluations are free and run automatically on publish. Task evaluations consume agent tokens but provide the only reliable signal of real-world effectiveness.
What This Means for Codex CLI Users
Codex CLI’s skill system uses AGENTS.md with a three-tier knowledge architecture: constitution files for project-wide rules, specialist files for domain-specific guidance, and skill files for reusable task patterns. Tessl integrates with Codex CLI through tessl init --agent codex2.
The practical workflow for a Codex CLI user looks like this:
- Write your skill as a SKILL.md following the Agent Skills specification.
- Lint with
tessl skill lintto catch structural issues. - Review with
tessl skill review --optimizeto improve instruction quality. - Generate scenarios with
tessl scenario generateto create test cases. - Evaluate with
tessl eval runto measure real behavioural impact. - Publish with
tessl skill publishto share on the registry. - Monitor with scheduled evaluation runs after model updates.
This lifecycle mirrors what Daniel has described as the aspiration to ‘treat skills like a production artefact.’ Tessl provides the missing infrastructure to make that practical.
The Durability Problem
Skills degrade. Models improve. A skill that provided a 30 per cent boost six months ago may now contradict the model’s native capabilities. Tessl’s scheduled evaluation pattern addresses this: run tessl eval run on a weekly cadence and compare scores against the historical baseline with tessl eval compare6.
When a skill’s with-skill score drops to match or fall below the baseline, you know it is time to retire or rewrite the skill rather than letting it silently degrade your agent’s performance.
This is the difference between treating skills as static configuration files and treating them as living software with a maintenance lifecycle.
Summary
- Tessl is a package manager and evaluation platform for AI agent skills, with a CLI, registry, and evaluation engine.
- Review evaluations check skill structure against best practices. Task evaluations measure real behavioural impact by comparing agent performance with and without the skill.
- Harbor provides the open-source statistical evaluation foundation, running multiple trials to account for inference stochasticity.
- Skill Creator V2 complements Tessl with parallel sub-agent execution, comparator agents, and benchmark mode for the authoring phase.
- Codex CLI users can integrate Tessl into their skill lifecycle with
tessl init --agent codex. - The cost of evaluation ($12 to $15 per cycle) is justified for team-shared and enterprise skills, but overkill for simple personal helpers.
- Skills degrade over time as models improve. Scheduled evaluation runs detect this before it causes silent performance loss.
-
Announcing Skills on Tessl: The Package Manager for Agent Skills ↩ ↩2
-
How to Evaluate AI Agents: An Introduction to Harbor ↩ ↩2 ↩3 ↩4 ↩5
-
Introducing Task Evals: Measure Whether Your Skills Actually Work ↩ ↩2
-
Improving Skill Creator: Test, Measure and Refine Agent Skills ↩ ↩2 ↩3 ↩4
-
I Used Skill Creator V2 to Improve One of My Agent Skills in VS Code ↩ ↩2