Codex CLI Skills: When a 10-Word Prompt Beats a Production Artefact
Codex CLI Skills: When a 10-Word Prompt Beats a Production Artefact
The skill ecosystem for AI coding agents has exploded. OpenAI’s skills catalogue ships system-level skills like skill-creator and skill-installer bundled with every Codex CLI installation1. On the Claude Code side, SkillsMP lists over 96,000 community skills2. Anthropic’s Skill Creator V2 adds scientific A/B evaluation with parallel test executions and percentage improvement scores3.
And yet the most productive pattern many senior developers have discovered is this: a 10-word prompt, saved as a one-line command, that just works.
This article explores the spectrum from throwaway prompt to production skill, offers a decision framework for where your next automation should land, and examines why over-engineering a skill can actively make things worse.
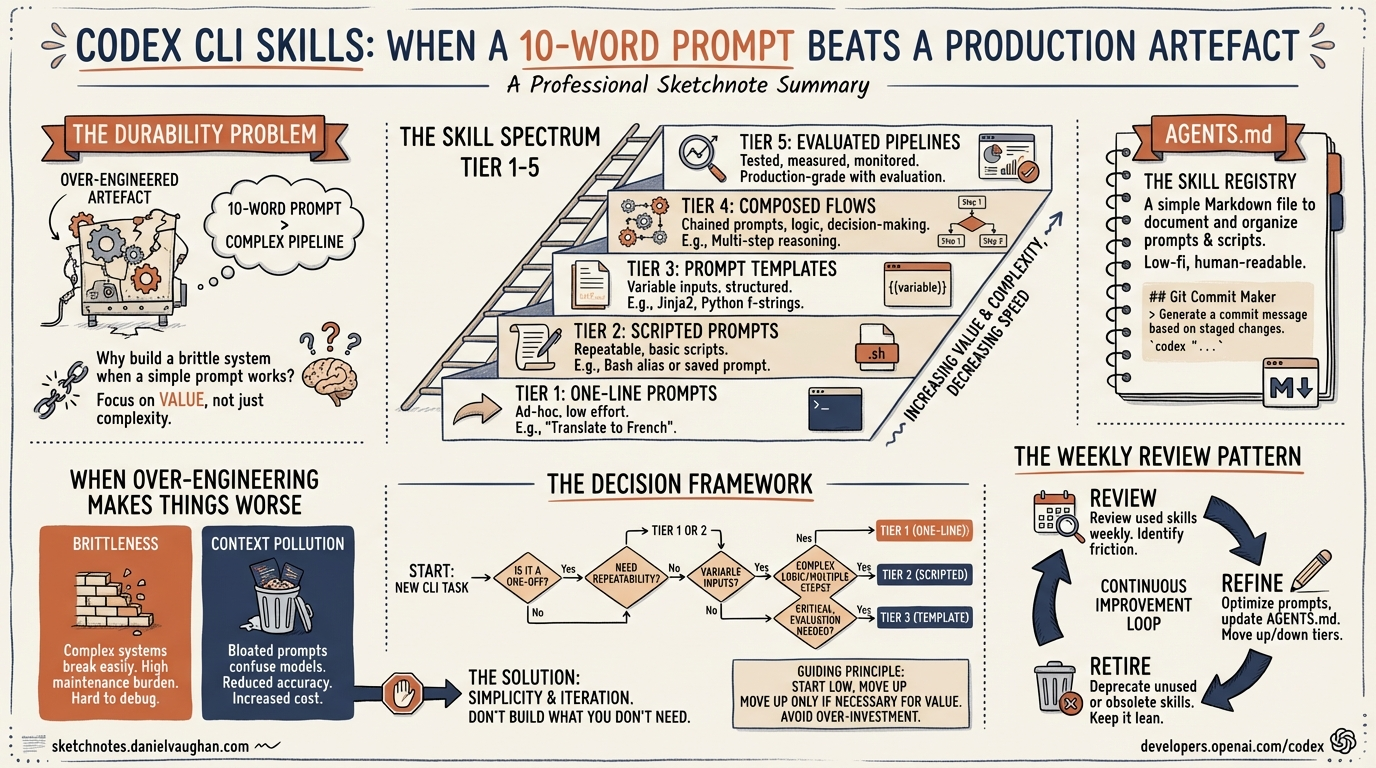
The Durability Problem
AI tooling changes at a pace that makes six-month-old code feel archaeological. A Codex CLI skill targeting the original single-agent model needed restructuring when multi-agent v2 arrived with TOML-defined subagents and path-based addressing4. Similarly, Codex CLI’s own custom prompts feature was deprecated in favour of skills within months of its launch. On the Claude Code side, a skill written in January 2026 against the old commands system needed rewriting by March when Anthropic merged commands and skills into a unified architecture5.
The implication is uncomfortable: the more moving parts a skill has, the faster it rots. A skill that shells out to specific CLI flags, references particular model names, or depends on a precise tool invocation chain becomes a maintenance liability the moment any upstream component shifts.
A 10-word prompt — “refactor this module to use dependency injection throughout” — has no moving parts. It survives model upgrades, CLI version bumps, and architectural changes because it operates at the level of intent rather than implementation.
The Skill Spectrum
Not every automation belongs at the same level of investment. The spectrum runs from zero-cost prompts through to fully evaluated production pipelines:
graph LR
A["One-line prompt"] --> B["/command<br>(saved prompt)"]
B --> C["SKILL.md<br>(structured instructions)"]
C --> D["Skill + scripts<br>(deterministic steps)"]
D --> E["Evaluated pipeline<br>(A/B tested, benchmarked)"]
style A fill:#e8f5e9
style B fill:#c8e6c9
style C fill:#fff9c4
style D fill:#ffe0b2
style E fill:#ffcdd2
Tier 1: The Prompt
A prompt typed directly into Codex CLI. Zero persistence, zero maintenance. If it works reliably, there is no reason to promote it further.
Example: codex "add error handling to all public methods in src/api/"
Tier 2: The Saved Command
Codex CLI has built-in slash command support — type / in the composer to open a menu with roughly 30 commands for model switching, session management, permissions, and code review6. For reusable prompts, Codex CLI originally supported custom prompts: markdown files in ~/.codex/prompts/ that became invocable as /prompts:draftpr with placeholder expansion ($1 through $9 for positional arguments)7. Custom prompts are now deprecated in favour of skills, which offer the same invocability plus implicit discovery and repository-level sharing.
In Claude Code, the equivalent is dropping a markdown file into .claude/skills/ where the filename becomes the /command8.
The cost is one file. The benefit is repeatability and discoverability — other developers on the team can invoke the command without knowing the underlying prompt.
Tier 3: The Structured Skill (SKILL.md)
A SKILL.md file with YAML frontmatter (name and description), markdown instructions, and optional subdirectories for scripts, references, and assets9. Codex CLI discovers skills automatically at startup and uses progressive disclosure to keep context usage low. The format is standardised across both Codex CLI and Claude Code since Anthropic open-sourced the Agent Skills specification in December 202510.
# Example: Codex CLI skill frontmatter (SKILL.md)
---
name: "migration-generator"
description: "Generate database migration files from schema changes"
---
The progressive disclosure model means Codex loads only the metadata initially (~50–100 tokens per skill) and fetches the full instructions only when the skill is selected11. This keeps the context window clean when you have dozens of installed skills.
Tier 4: Skill With Scripts
Adding a scripts/ directory to a skill introduces deterministic steps — shell scripts, Python utilities, or validation checks that run outside the LLM’s reasoning loop. This is where skills start to resemble traditional tooling and where maintenance cost climbs sharply.
Tier 5: Evaluated Pipeline
Anthropic’s Skill Creator V2 operates in four modes: Create, Eval, Improve, and Benchmark3. The eval pipeline uses four composable sub-agents running in parallel — executor, grader, comparator, and analyser — with a 60/40 training/test split to prevent overfitting12. It produces percentage improvement scores and interactive browser-based review dashboards.
This is rigorous. It is also token-heavy. A single benchmark run consumes roughly 70,000–75,000 tokens per evaluation13, and the default configuration runs 10–20 parallel comparisons, so a full cycle can burn through a meaningful portion of a daily API budget.
The Decision Framework
The question is not “should I write a skill?” but “at which tier should this automation live?” Here is a practical framework:
flowchart TD
A["Does the prompt work<br>reliably every time?"] -->|Yes| B["Does anyone else<br>need to use it?"]
A -->|No| C["Does it need file context,<br>tool access, or multi-step logic?"]
B -->|No| D["Tier 1: Keep it as a prompt"]
B -->|Yes| E["Tier 2: Save as /command"]
C -->|No| F["Improve the prompt wording"]
C -->|Yes| G["Does it touch production data<br>or run unattended?"]
G -->|No| H["Tier 3: Write a SKILL.md"]
G -->|Yes| I["Tier 4-5: Invest in scripts<br>and evaluation"]
The key insight: most automations should stop at Tier 2. The jump from a saved command to a structured SKILL.md should be motivated by a concrete failure mode — the prompt sometimes produces wrong output, it needs to invoke specific tools, or it requires multi-step orchestration that natural language cannot reliably express.
AGENTS.md: The Constitution That Makes Skills Optional
Codex CLI’s AGENTS.md system provides a layering mechanism that often eliminates the need for standalone skills entirely14. AGENTS.md files are discovered hierarchically — Codex walks from the project root down to the current working directory, loading each level’s instructions15.
This creates natural tiers:
- Root AGENTS.md — project-wide conventions (coding style, testing requirements, architectural constraints). This functions as a constitution.
- Directory-level AGENTS.md — specialist instructions for specific subsystems (
/api/AGENTS.mdwith REST conventions,/infra/AGENTS.mdwith Terraform patterns). - Skills — cross-cutting workflows that do not belong to any single directory.
When the constitutional and specialist layers are well-written, the agent already knows how to handle most tasks correctly. Skills become necessary only for workflows that cross boundaries or require deterministic script execution.
When Over-Engineering Makes Things Worse
There are three specific failure modes when a skill is over-engineered relative to its purpose:
False Precision
A skill that specifies exact file paths, line numbers, or implementation details constrains the agent unnecessarily. LLMs reason well about intent; they reason poorly when forced to follow overly prescriptive step-by-step instructions that do not match the current state of the codebase.
Context Window Pollution
Each skill adds approximately 50–100 tokens of metadata to the agent’s initial context11. When the full instructions are loaded, a verbose skill can consume thousands of tokens. With Codex CLI’s 192,000-token context window16, this sounds manageable in isolation — but compound it across 30+ installed skills, subagent definitions, AGENTS.md files, and the actual codebase, and you are burning context on instructions rather than reasoning.
A vague skill description like “helps with databases” will fire on irrelevant prompts and pollute the context further11.
Brittleness
A skill with six shell scripts, three API calls, and a custom validation step is a skill with six points of failure. When Codex CLI updates its sandbox model, or when an external API changes its response format, the skill breaks silently. The developer who wrote it has moved on. The developer who inherits it spends more time debugging the skill than they would have spent doing the task manually.
The Weekly Review Pattern
Rather than investing heavily in skill creation upfront, a more sustainable approach is periodic review. The pattern:
- Week 1: Use ad-hoc prompts. Note which ones you repeat.
- Week 2: Promote repeated prompts to Tier 2 saved commands.
- Weekly thereafter: Have the agent itself review saved commands that have not changed recently and suggest improvements or consolidation.
This can be automated in Codex CLI using a subagent that reads the skills directory, checks git history for staleness, and proposes updates:
codex "Review all skills in ~/.codex/skills/. For each one, check if its instructions reference any deprecated flags, outdated model names, or removed features. Suggest updates or recommend deletion if the skill is no longer useful."
This is, notably, a single prompt — not a skill. It does not need to be one.
When Evaluation Is Worth the Spend
Anthropic’s Skill Creator V2 evaluation pipeline is genuinely useful in specific contexts3:
- Enterprise skills that automate end-to-end workflows (ticket creation → ADR review → implementation → PR) where a 11% improvement translates to hundreds of saved engineer-hours per month.
- Unattended skills running in CI/CD or scheduled tasks where silent failures are costly.
- Cross-team skills where consistency across dozens of developers justifies the upfront investment.
For a personal formatting helper or a project-specific refactoring command, burning hundreds of thousands of tokens to learn it improved by 11.4 per cent is vanity metrics territory. Save the tokens for actual work.
Practical Recommendations
-
Start with AGENTS.md. Get the constitutional and specialist layers right before creating any skills. A well-written root AGENTS.md eliminates the need for half the skills you think you need.
-
Write descriptions, not instructions. When you do create a SKILL.md, invest in a precise, keyword-rich description. Codex’s progressive disclosure model means the description is all that is loaded initially — it determines whether the skill fires at all11.
-
Prefer Tier 2 over Tier 3. A saved command with a good description is faster to create, easier to maintain, and often just as effective as a structured SKILL.md.
-
Delete aggressively. Skills that have not been invoked in 30 days are candidates for deletion. Stale skills consume context and create confusion.
-
Reserve evaluation for high-value workflows. If the skill does not save at least 10x its evaluation cost in developer time, the evaluation is not worth running.
Conclusion
The skill ecosystem in 2026 is mature, standardised, and impressively powerful. But maturity brings the temptation to over-engineer. The developers getting the most value from Codex CLI are often the ones with the fewest skills — a tight AGENTS.md constitution, a handful of well-described saved commands, and the discipline to let a good prompt remain a prompt.
The 10-word prompt is not a sign of laziness. It is a sign that you understand what the agent is actually good at.
Citations
-
Skills Catalog for Codex — OpenAI, GitHub, 2026 ↩
-
SkillsMP: 96,751+ Claude Code Skills Directory — Julio Pessan, Medium, 2026 ↩
-
Anthropic Skill Creator Measures If Your Agent Skills Work — Joe Njenga, Medium, March 2026 ↩ ↩2 ↩3
-
Codex CLI: The Definitive Technical Reference — Blake Crosley, 2026 ↩
-
Claude Code Merges Slash Commands Into Skills — Joe Njenga, Medium, 2026 ↩
-
Slash Commands in Codex CLI — OpenAI Developer Docs, 2026 ↩
-
Custom Prompts — Codex Developer Docs — OpenAI, 2026. Note: custom prompts are now deprecated in favour of skills. ↩
-
Extend Claude with Skills — Claude Code Docs — Anthropic, 2026 ↩
-
Agent Skills — Codex Developer Docs — OpenAI, 2026 ↩
-
CLAUDE.md, AGENTS.md, and Every AI Config File Explained — DeployHQ, 2026 ↩
-
Codex CLI Agent Skills: 2026 Install and Usage Guide — ITECS Online, 2026 ↩ ↩2 ↩3 ↩4
-
Anthropic Skill Creator 2.0 Update: Evals, Benchmarks, and Multi-Agent Testing — The Tool Nerd, 2026 ↩
-
Claude Code Skill Creator: How to Test and Benchmark Your Skills — Nathan Onn, 2026. Benchmark data shows ~74,000 tokens per evaluation run. ↩
-
Custom Instructions with AGENTS.md — Codex Developer Docs — OpenAI, 2026 ↩
-
How to Set Up OpenAI Codex: AGENTS.md, MCP Servers, Skills — LLMx, 2026 ↩
-
Context Management Strategies for OpenAI Codex — Alex Merced, Lakehouse Blog, 2026 ↩