Rod Johnson Is Back — and He's Bringing Agent AI to the JVM
Rod Johnson Is Back — and He’s Bringing Agent AI to the JVM
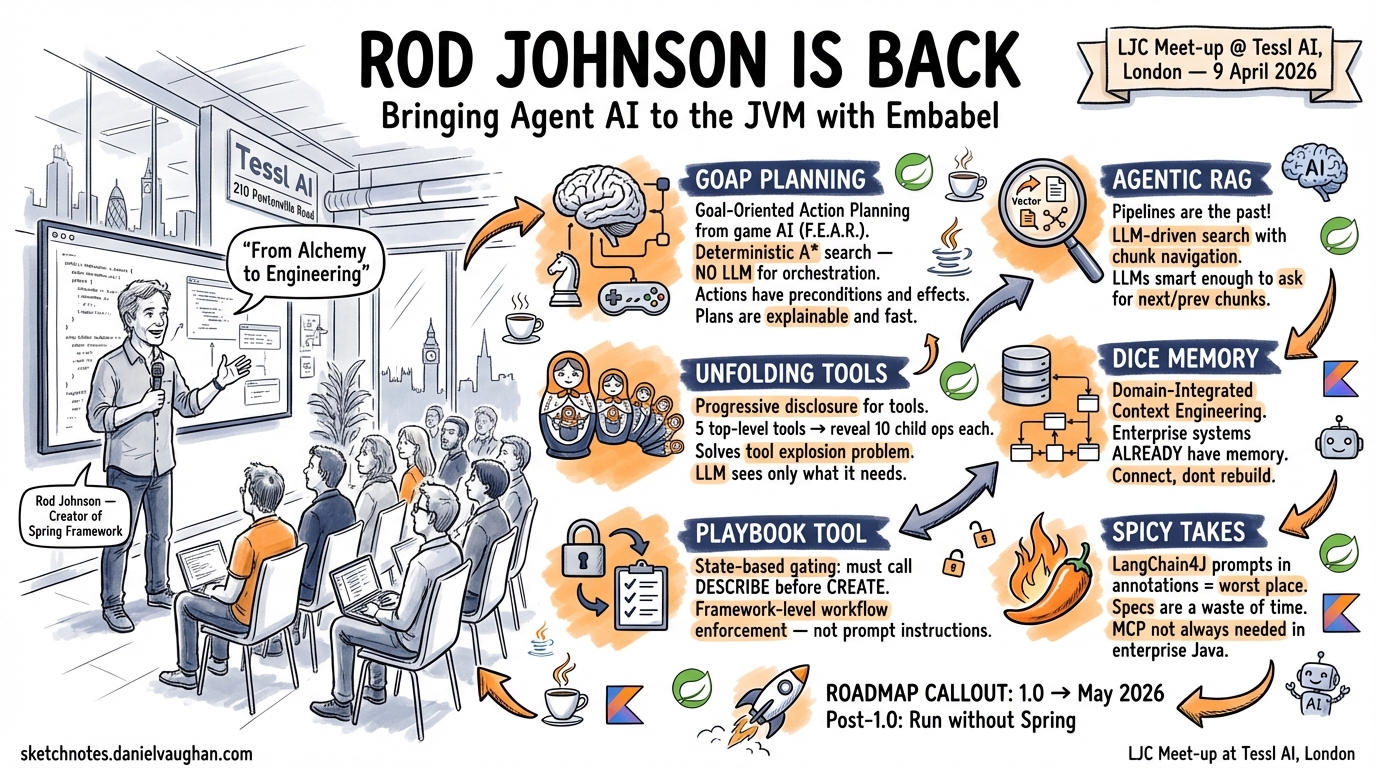
I spent this evening watching Rod Johnson — the creator of the Spring Framework — demo his new AI agent framework, Embabel, at the LJC Meet-up at Tessl in London. The event, “Java and Gen AI: JVM Agents With Embabel,” was hosted by the London Java Community at Tessl AI’s offices on Pentonville Road. I walked in expecting a competent Java wrapper around LLM APIs. I walked out thinking the JVM agent ecosystem just got its most important project.
Photo: Rod Johnson presenting Embabel at the LJC Meet-up at Tessl, London, 9 April 2026
This is a write-up of the talk, with additional context from my own research into the framework.
The Spring Analogy That Sets the Frame
Rod opened with a comparison that immediately told you where he was aiming. Spring AI, he said, is to Embabel as the Servlet API was to Spring MVC. Spring AI gives you the low-level plumbing — model clients, prompt templates, tool calling. Embabel gives you the framework: planning, goals, actions, domain models, and the kind of opinionated architecture that made Spring itself so successful.
If you were in the Java ecosystem in the early 2000s, you know what Rod Johnson did with Spring. He took a landscape of bloated J2EE containers and XML configuration and replaced it with something clean, testable, and pragmatic. Watching him present Embabel, you could see the same instincts at work: take a landscape of chaotic LLM wrappers and ad-hoc agent scripts, and impose enough structure to make it engineering rather than alchemy.
That is, in fact, the title of one of his blog posts: “From Alchemy to Engineering.”
GOAP: Borrowing Planning from Game AI
The most architecturally interesting idea in Embabel is its planning layer, and it does not use an LLM.
Most agent frameworks — LangGraph, CrewAI, AutoGen — either ask the LLM to plan (“think step by step about how to accomplish this goal”) or hard-code the plan in application logic. The first approach is unreliable. The second is brittle. Embabel takes a third path: Goal-Oriented Action Planning, or GOAP, borrowed from game AI.
GOAP is the algorithm used to make NPCs in games like F.E.A.R. plan believable sequences of actions. It works by defining a state space (what the world looks like now), a set of actions (what the agent can do, with preconditions and effects), and goals (desired world states). A deterministic A* search finds the cheapest sequence of actions that transforms the current state into the goal state.
In Embabel, the “world” is the set of typed domain objects the agent has produced so far. Actions are Kotlin or Java functions annotated with their preconditions (what types they need as input) and effects (what types they produce). The GOAP planner discovers these actions from your code and plans toward the goal — entirely without LLM involvement.
This means the plan is deterministic, explainable, and fast. The LLM is used where it excels — natural language understanding, content generation, tool invocation — but the orchestration is handled by an algorithm with forty years of research behind it.
Rod also mentioned an alternative planner called Utility AI, which skips explicit goals and instead evaluates: “What is the highest-value thing I can do right now?” This suits open-ended scenarios like chatbots where there is no terminal goal state.
I found myself thinking about how this compares to the way I orchestrate Codex CLI agents. My multi-agent workflows use sequential chains and wave-based phases — essentially manual planning. GOAP would automate the sequencing while keeping it deterministic. It is a genuinely different approach to the planning problem.
Unfolding Tools: Solving the Tool Explosion
One of the sharpest practical innovations Rod demonstrated was what Embabel calls “unfolding tools.”
The problem is real and familiar to anyone running agents with many capabilities: LLM performance degrades as you add more tools. Rod gave a concrete example — five document stores, each with ten search operations. That is fifty tools. Present all fifty to the LLM and you get slower responses, higher token costs, and worse tool selection accuracy.
Embabel’s solution is hierarchical. You present five top-level tools: “Access user documents,” “Access policy documents,” “Access product catalogue,” and so on. When the LLM calls one of these, the framework rewrites the tool-calling history to expose only that tool’s child operations. The LLM then sees the ten specific search methods for the selected store, without ever having been shown the other forty.
This is progressive disclosure at the tool-call level, within a single conversation turn. It reminded me of how Codex CLI skills work — the LLM gets a small frontmatter description first and only loads the full skill body if it is interested. Same underlying principle (too many options degrade performance), but solved at different architectural layers.
The Playbook Tool: State-Based Gating
Rod demonstrated something he called the “playbook tool,” which I believe may be unique to Embabel. It unlocks tools based on what the agent has already accomplished in the current session.
His example: a repository management tool with create, delete, find, and describe operations. To call create, the LLM must first have called describe for that entity type — it needs to know the schema before it can create a record. Delete, however, can be called without that precondition.
This is workflow enforcement at the framework level. It is not a prompt instruction that the LLM might ignore. It is not a rigid scripted pipeline. It is a flexible constraint system: these tools become available when these preconditions are met.
In the Codex CLI world, the closest equivalent is a PreToolUse hook that tracks state in a file and rejects calls that violate the workflow. It works, but it is a workaround. Embabel makes it a first-class concept.
Agentic RAG: “Pipelines Are the Past”
Rod was emphatic about this: traditional RAG pipelines — embed your documents, chunk them, vector-search for similar content, stuff it in the prompt — are fundamentally flawed.
His critique was specific. First, vector search is not the right search for all cases. Some queries need keyword matching, some need structural queries, some need graph traversal. Second, chunking creates boundary problems. Whatever chunking strategy you use, some chunk boundaries will split meaningful content. Your retrieved context will miss things or return fragments that do not make sense in isolation.
Embabel’s alternative is what Rod calls agentic RAG. Instead of a pipeline that runs before the LLM sees the query, you give the LLM tools to search. The ToolishRag class in Embabel wraps a search operations interface — you implement whichever search methods make sense for your data store: vector search, BM25 text search, regular expression search, even graph traversal with Neo4J.
The key insight is chunk navigation. If the LLM retrieves a chunk and it looks like it was cut off mid-thought, it can request the next or previous chunk. LLMs are smart enough to recognise incomplete information and ask for more. This elegantly solves the chunking boundary problem without requiring perfect chunking.
“LLMs are smart enough to do this,” Rod said. “This is definitely an area where it actually does make sense to give your LLM more time.”
I noted that Codex CLI already does a form of agentic RAG through MCP knowledge servers — the agent decides when and what to search, using tools provided by servers like Context7 or custom implementations. The architectural parallel is strong. The difference is that Embabel integrates RAG tightly with its domain model and provides chunk navigation out of the box, while Codex CLI delegates the sophistication to whichever MCP server you connect.
DICE: Memory That Knows Your Domain
Perhaps the most enterprise-relevant idea in the talk was DICE — Domain-Integrated Context Engineering — Embabel’s approach to agent memory.
Rod’s argument was blunt: enterprise systems already have memory. My bank knows my balance, my transaction history, my account types. All structured. All typed. Most agent memory frameworks treat memory as a greenfield problem — build a new vector store, create a new knowledge graph. DICE argues that agent memory should integrate with existing domain models rather than duplicating them in a parallel store.
In practice, this means Embabel’s context engineering works with typed domain objects that map to your existing Spring entities. The LLM does not operate on unstructured text blobs representing “memories” — it operates on business objects with schemas, relationships, and validation.
This is a direct challenge to the memory ecosystem that has grown up around tools like Codex CLI, where memory solutions (AgentMemory, Memorix, Basic Memory) build their own stores. Rod is saying: the memory already exists in your enterprise systems. Connect to it, do not rebuild it.
Spicy Takes
Rod did not hold back on opinions, and the audience seemed to enjoy it.
On LangChain4J: Rod questioned the design choice of putting prompts in annotations, arguing that prompts are content rather than code and should be managed accordingly — versioned, A/B tested, and evaluated separately from the codebase.
On specifications: “I honestly think that specs are a waste of time. This space is moving so quickly that even an open source project struggles to keep up. Good luck with any spec initiative.” He was referring to efforts to standardise agent protocols. Given how quickly MCP went from announcement to ubiquity, and how Agent2Agent is already challenging its assumptions, I think he has a point.
On MCP in enterprise: While acknowledging MCP’s importance (Embabel supports both consuming and exporting MCP), Rod argued that for enterprise Java shops, native Spring service integration is more natural and more secure than routing everything through MCP. “You don’t have to go through the hoops of the MCP. This is part of the reason that it makes a lot of sense to do your GenAI in Java if your applications are in Java.”
On local models: Rod was enthusiastic about smaller models running on-device. He noted that GPT 4.1 mini outperforms the small GPT 5 models for tool calling, and that tool calling in smaller models is becoming good enough for production use. “Don’t only consider the development of the massive cloud models. Consider the development in the smaller models, because you might be able to run some of those in-house.” He lamented that his 32GB laptop was marginal for the demo and mentioned a 128GB M5 Max waiting for him back in Australia.
On Codex CLI skills: Rod had clearly studied the skills specification and was respectful but critical. He praised the progressive disclosure pattern — “That’s a fantastic idea. It’s also a great idea to have a consistent structure so that different frameworks and agents can handle it.” But he was uneasy about the script execution model: “The part that’s a little iffy is the notion of scripts. Skills can have scripts in there, and it is a little disturbing that they don’t even tell you what version of Python or what version of dependencies.”
The Roadmap
Embabel is targeting a 1.0 release within six weeks — roughly May 2026. The key pre-1.0 work is moving skills support and sandbox support from the experimental package into the core framework. Post-1.0, the most significant planned change is the ability to run Embabel independently of Spring — which would dramatically widen its potential user base.
The sandbox module currently has two implementations: Docker (production-ready) and a local “just run on my machine” option for testing. Spring Security integration is coming for MCP endpoints.
Why This Matters Beyond the JVM
Even if you never write a line of Kotlin or Java, several of Embabel’s ideas are worth paying attention to.
Deterministic planning over LLM planning. GOAP shows that you can get reliable multi-step orchestration without asking an LLM to plan. The LLM handles the parts that require language understanding; the planner handles sequencing. This is a design principle that any agent framework could adopt.
Tool hierarchy as a performance lever. The unfolding tools pattern is a general solution to the tool explosion problem. As MCP servers proliferate and agents gain access to dozens or hundreds of tools, some form of hierarchical tool presentation will become necessary. Embabel has a concrete, working implementation.
Enterprise memory integration over greenfield memory. The DICE philosophy — connect to existing data rather than building parallel stores — is relevant to any enterprise deploying agents, regardless of language or framework.
Workflow enforcement at the framework level. The playbook tool’s state-based gating is the kind of safety mechanism that the broader agent ecosystem is still figuring out. Prompt-based guardrails are not reliable enough for enterprise workflows. Framework-level constraints are.
Rod Johnson reshaped how an entire generation of developers built Java applications. Watching him apply those same architectural instincts to agent AI, I suspect he might be about to do it again — at least for the JVM ecosystem. Whether Embabel can compete with the Python-first momentum of LangGraph and CrewAI remains to be seen. But the ideas are strong, the engineering is clean, and the man clearly has not lost his edge.
Summary
- Embabel is Rod Johnson’s new JVM-based AI agent framework, positioned above Spring AI (“Spring AI is to Embabel as the Servlet API is to Spring MVC”). It targets enterprise Java/Kotlin teams building production agent systems.
- GOAP (Goal-Oriented Action Planning) from game AI provides deterministic, non-LLM planning — the agent’s orchestration is handled by A* search over typed actions and goals, not by asking the LLM to “think step by step.”
- Unfolding tools solve the tool explosion problem by presenting top-level tools and revealing child tools on demand — progressive disclosure at the tool-call level within a single conversation turn.
- The playbook tool gates tool access based on workflow state — “you must call describe before you can call create” — enforced at the framework level rather than through prompt instructions.
- Agentic RAG replaces pipeline RAG (embed-chunk-retrieve-augment) with LLM-driven search. The agent gets tools to search across multiple backends (vector, text, graph) and can navigate chunks (request next/previous) to solve boundary problems.
- DICE (Domain-Integrated Context Engineering) argues that enterprise agent memory should integrate with existing domain models rather than building greenfield vector stores.
- Rod questioned LangChain4J’s annotation-based prompt design, was sceptical of specification efforts (“specs are a waste of time”), and enthusiastic about smaller local models for tool calling.
- 1.0 is targeted for May 2026, with skills and sandbox support moving into core. Post-1.0: running independently of Spring.
Rod Johnson’s talk was at the LJC Meet-up at Tessl — Java and Gen AI: JVM Agents With Embabel, hosted by the London Java Community at Tessl AI Limited, 210 Pentonville Road, London, on 9 April 2026. The Embabel framework is open source at github.com/embabel/embabel-agent.