Subscription vs API Key: What Heavy Users Actually Consume and What It Costs on Codex CLI
Subscription vs API Key: What Heavy Users Actually Consume and What It Costs on Codex CLI
Every Codex CLI user faces the same fork: authenticate with your ChatGPT subscription (Plus, Pro, Business) or plug in an OpenAI API key and pay per token. At light usage, the subscription wins on simplicity. At heavy usage, the economics diverge dramatically — and the right choice depends on how much you actually consume.
This article grounds that decision in real usage data from developer reports, community forums, and Anthropic’s published statistics (the closest comparable data to Codex CLI). It then models costs across every billing path available in April 2026 and answers: at what volume does each subscription plan break, and when does the API key become the only viable option?
The Billing Paths
As of April 2026, there are four ways to pay for Codex CLI usage12:
| Path | How It Works | Rate Limits | Billing |
|---|---|---|---|
| Subscription (Plus/Pro) | Authenticate via ChatGPT account | Rolling 5-hour windows, dynamic limits | Flat monthly fee |
| Business Standard Seat | ChatGPT Business workspace | Plan limits + optional credit top-ups | $20/seat/month + credits |
| Business Codex-Only Seat | Codex access only, no ChatGPT | No rate limits | $0/seat + token consumption |
| API Key (Direct) | OpenAI API key in config.toml |
Standard API rate limits only | Per-token, pay-as-you-go |
What Heavy Users Actually Consume: The Data
Before modelling costs, we need to establish what developers actually use. The figures below are drawn from published data, community reports, and usage tracking tools.
Per-Session Token Consumption
| Metric | Tokens | Source |
|---|---|---|
| Median context per turn | ~96K | Codex CLI usage spike analysis3 |
| p95 context per turn | ~200K | Same source3 |
| Session startup overhead | 21-22K | Up from 12-15K in earlier versions3 |
| Typical session (simple task) | 10K-100K | Faros.ai engineering guide4 |
| Typical session (agent workflow) | 200K-500K | Morph AI coding cost study5 |
| Baseline session cost (Sonnet rates) | $6-8 | Morph AI coding cost study5 |
A critical finding: 60-80% of tokens in agentic sessions are waste — spent on finding code, re-reading context, and retrying, not on writing code5. Shell tool outputs alone account for 90.3% of all tool-output characters3.
Per-Developer Daily and Monthly Consumption
Anthropic publishes the most detailed usage data for a comparable agentic CLI tool (Claude Code). These figures provide the best available proxy for Codex CLI heavy usage:
| Developer Profile | Daily Cost (API rates) | Monthly Cost | Estimated Tokens/Week | Source |
|---|---|---|---|---|
| Light (1-2 sessions/day) | $2-5 | $50-100 | ~1-3M | Verdent Guides6 |
| Medium (3-5 hours/day) | $6-12 | $100-200 | ~3-10M | Anthropic published average4 |
| Heavy (multi-agent workflows) | $20-60+ | $400-1,200+ | ~10-50M | Morph AI, Verdent56 |
| Extreme (documented outlier) | ~$60 | ~$1,875 | ~312M | 10B tokens over 8 months6 |
Anthropic reports that the average developer spends $6/day, and 90% of developers stay below $12/day4. This means 90% of developers consume fewer than ~5M tokens/week.
The most extreme documented individual case — 10 billion tokens over eight months — works out to ~312M tokens/week6. That user’s estimated API cost was over $15,000 for the period, versus $800 on the $100/month Max subscription — a 93% saving that illustrates both the scale of heavy usage and the value of subscriptions when they can absorb the volume.
Community-Reported Pain Points
Real developer reports confirm these ranges37:
- A single Codex CLI prompt consuming 7% of weekly Plus limits (~600K tokens based on limit structure)
- One user exhausting 97% of weekly allowance after just three prompts
- A Plus user burning 25% of weekly limit in 30 minutes
- A one-line configuration change consuming ~2% of the 5-hour quota
These reports align with the 96K median-context-per-turn figure: even “light” usage of 10-20 turns can consume 1-2M tokens.
The Realistic Usage Tiers
Based on this data, here are the usage tiers this article analyses:
| Tier | Tokens/Week | Who | Monthly API Cost (5.4-mini) |
|---|---|---|---|
| Light | 2M | Part-time CLI user, 1-2 sessions/day | ~$10 |
| Medium | 10M | Full-time developer, 4-6 sessions/day | ~$45 |
| Heavy individual | 50M | Power user, multi-agent workflows all day | ~$225 |
| Extreme individual | 300M | The documented outlier ceiling | ~$1,350 |
| Team of 10 (medium) | 100M | 10 medium-usage developers | ~$450 |
| Team of 50 (medium + CI/CD) | 1B | 50 developers plus automated pipelines | ~$4,500 |
One billion tokens per week is a team-level volume — realistic for organisations that have embedded Codex CLI into CI/CD pipelines, automated review gates, and always-on orchestration. It is not achievable by a single developer through interactive use.
Token Mix Assumptions
For the cost calculations that follow, we assume this token mix (consistent across all tiers):
| Component | Share | Why |
|---|---|---|
| Input (uncached) | 24% | Fresh context, new files, first turns |
| Input (cached) | 56% | Prefix caching in sustained sessions (70% cache hit rate)8 |
| Output | 20% | Agent edits are targeted; prompts are long |
This 70% cache hit rate reflects Codex CLI’s prefix caching in sustained sessions. Short sessions or frequent context switches reduce it to 30-50%, significantly increasing costs (see Cache Efficiency section below).
Can Subscriptions Handle a Billion Tokens Per Week?
No. Not even close.
Plus ($20/month)
Plus provides 20-100 GPT-5.4 messages per 5-hour window1. Estimating ~8,000 tokens per message (4K input + 4K output), that is:
- Per window: 160K-800K tokens
- Per day (3 usable windows): 480K-2.4M tokens
- Per week: 2.4M-12M tokens
- Per month: ~10M-48M tokens
Maximum capacity: ~48M tokens/month — roughly 1/80th of the target volume.
The Plus subscription effectively provides ~$0.42-2.08 per million tokens (dividing $20 by the token volume). That is extraordinarily cheap — far below API rates — but the volume ceiling makes it irrelevant for heavy users.
Pro 5× ($100/month)
Five times Plus limits:
- Per week: 12M-60M tokens
- Per month: ~48M-240M tokens
Maximum capacity: ~240M tokens/month — roughly 1/16th of the target.
Pro 20× ($200/month)
Twenty times Plus limits:
- Per week: 48M-240M tokens
- Per month: ~192M-960M tokens
Maximum capacity: ~960M tokens/month — still short of 1B/week (4.3B/month), but closer.
Pro 20× might sustain 240M tokens/week at the upper range of its dynamic limits during off-peak hours, but a sustained billion tokens/week is 4× beyond its ceiling. Additionally, the promotional 10× boost (through May 31, 2026) temporarily doubles effective Pro limits, but relying on promotional capacity for production workloads is not a viable strategy1.
The Subscription Ceiling
| Plan | Monthly Price | Max Tokens/Month | Effective $/M Tokens | Can Hit 1B/Week? |
|---|---|---|---|---|
| Plus | $20 | ~48M | ~$0.42 | ❌ (1/80th) |
| Pro 5× | $100 | ~240M | ~$0.42 | ❌ (1/16th) |
| Pro 20× | $200 | ~960M | ~$0.21 | ❌ (1/4th) |
The effective per-token rate on subscriptions is absurdly cheap — $0.21-0.42 per million tokens — but the volume is hard-capped. Subscriptions are subsidised access with a ceiling, not unlimited access at a fixed price.
API Key: The Only Path to a Billion Tokens Per Week
For heavy users, the API key is the only option that scales. Here is what 1B tokens/week costs across every model, using the token mix defined above (240M uncached input + 560M cached input + 200M output)2:
Standard API Rates
| Model | Uncached Input Cost | Cached Input Cost | Output Cost | Weekly Total | Monthly Total |
|---|---|---|---|---|---|
| GPT-5.4 | $600 | $140 | $3,000 | $3,740 | $14,960 |
| GPT-5.4-mini | $180 | $42 | $900 | $1,122 | $4,488 |
| GPT-5.4-nano | $48 | $11.20 | $250 | $309 | $1,237 |
| GPT-5.3-Codex | $420 | $98 | $2,800 | $3,318 | $13,272 |
Relative Pricing: How Models Compare
The raw dollar figures above obscure an important question: how much cheaper (or more expensive) is each model relative to the others? The table below indexes every model against GPT-5.4 as the baseline (1.00×), using the weighted weekly cost at 1B tokens/week:
| Model | Weekly Cost | Relative to GPT-5.4 | Cost Index | Plain English |
|---|---|---|---|---|
| GPT-5.4-pro | $24,600 | 6.58× | ██████████████████████████ | 6.6× more expensive — reasoning-only, not for routine coding |
| GPT-5.4 (priority) | $7,480 | 2.00× | ████████ | 2× baseline — guaranteed low-latency SLA |
| GPT-5.4 | $3,740 | 1.00× | ████ | Baseline — frontier capability |
| GPT-5.3-Codex | $3,318 | 0.89× | ███▌ | 11% cheaper — code-specialised, similar output quality |
| GPT-5.4-mini | $1,122 | 0.30× | █▏ | 70% cheaper — the sweet spot for most tasks |
| GPT-5.4-nano | $309 | 0.08× | ▎ | 92% cheaper — batch/scripted work only |
Key insight: GPT-5.4-mini delivers ~80% of GPT-5.4’s coding capability at 30% of the cost. For a heavy user, defaulting to mini and escalating to full 5.4 only when needed saves $10,472/month — more than many developers’ monthly salary.
The priority tier (2× standard) is relevant for latency-sensitive production pipelines where response time matters more than cost. At 1B tokens/week, the premium is $3,740/week — substantial, but justified if agent idle time costs more than the surcharge.
GPT-5.4-pro at $30/$180 per million tokens (input/output) is 6.6× the baseline and has no cached input discount. At heavy volume, it costs $24,600/week ($98,400/month). This model is designed for complex multi-step reasoning — research problems, novel algorithm design — not routine coding tasks. Using it as a default model is a billing catastrophe.
The Blended Strategy Visualised
Most heavy users should not pick a single model. Here is how different blending strategies compare:
| Strategy | Model Mix | Monthly Cost | vs All-5.4 | vs All-mini |
|---|---|---|---|---|
| All GPT-5.4 | 100% 5.4 | $14,960 | — | +233% |
| Conservative blend | 50% mini / 40% 5.4 / 10% nano | $9,168 | −39% | +104% |
| Recommended blend | 70% mini / 25% 5.4 / 5% nano | $6,943 | −54% | +55% |
| Aggressive blend | 85% mini / 10% 5.4 / 5% nano | $5,320 | −64% | +19% |
| All GPT-5.4-mini | 100% mini | $4,488 | −70% | — |
| All GPT-5.4-nano | 100% nano | $1,237 | −92% | −72% |
| Budget batch | 100% mini (batch) | $2,244 | −85% | −50% |
The recommended 70/25/5 blend saves $8,017/month compared to all-5.4 while retaining frontier capability for the tasks that need it. The question each developer must answer: which 25% of my tasks genuinely need GPT-5.4?
Batch API Rates (50% Discount)
For non-interactive workloads (CI/CD, code review pipelines, bulk refactoring), the Batch API halves costs2:
| Model | Weekly Total | Monthly Total | Savings vs Standard |
|---|---|---|---|
| GPT-5.4 | $1,870 | $7,480 | 50% |
| GPT-5.4-mini | $561 | $2,244 | 50% |
| GPT-5.4-nano | $155 | $619 | 50% |
| GPT-5.3-Codex | $1,659 | $6,636 | 50% |
Flex Processing (50% Discount, Variable Latency)
Flex processing offers the same 50% discount as Batch but with shorter turnaround — suitable for background tasks that don’t need real-time responses2:
| Model | Weekly Total | Monthly Total |
|---|---|---|
| GPT-5.4 | $1,870 | $7,480 |
| GPT-5.4-mini | $561 | $2,244 |
| GPT-5.4-nano | $155 | $619 |
The Model Selection Lever
The difference between GPT-5.4 and GPT-5.4-mini at this volume is $10,472/month. The difference between GPT-5.4 and GPT-5.4-nano is $13,723/month. Model selection is the single largest cost lever available.
For most Codex CLI workflows, GPT-5.4-mini handles 70-80% of tasks at near-equivalent quality to GPT-5.48. A blended strategy using profiles:
[profiles.default]
model = "gpt-5.4-mini" # 70% of tasks
[profiles.complex]
model = "gpt-5.4" # 25% of tasks
[profiles.bulk]
model = "gpt-5.4-nano" # 5% of tasks
Blended weekly cost (700M mini + 250M 5.4 + 50M nano):
| Component | Tokens/Week | Weekly Cost |
|---|---|---|
| GPT-5.4-mini (70%) | 700M | $785 |
| GPT-5.4 (25%) | 250M | $935 |
| GPT-5.4-nano (5%) | 50M | $15 |
| Blended total | 1B | $1,736/week ($6,943/month) |
That is 54% cheaper than running everything on GPT-5.4 ($14,960/month) and only 55% more than running everything on GPT-5.4-mini ($4,488/month) — a reasonable premium for having frontier capability available when needed.
Business Codex-Only Seats: API Rates Without the Hassle
Codex-only seats on ChatGPT Business bill at token consumption rates with no fixed monthly fee and no rate limits9. For organisations, this provides:
- Per-user spend controls — admins set monthly credit limits per seat or per user10
- Centralised billing — all usage appears on the workspace invoice
- No rate limits — unlike Plus/Pro, consumption is not gated by 5-hour windows
- Usage monitoring — admins can view per-user and per-seat-type consumption in the workspace billing dashboard10
The token rates for Codex-only seats align with standard API pricing9. For a team, this means the same costs as API key billing but with enterprise controls layered on top.
Standard Business Seats and Codex CLI
A Standard Business seat ($20/month) includes Codex CLI access with the same rate limits as Plus9. Critically, Codex usage on Standard Business seats does consume from the seat’s allocation and is visible to workspace admins — admins can see per-user credit consumption and set spend limits by seat type or by individual user10. This means:
- Usage is monitored: yes, workspace admins see Codex consumption
- Usage is capped: Standard seats are subject to the same 5-hour rolling window limits as Plus
- Overage billing: if credits are exhausted, usage stops unless the admin has enabled additional credit purchasing
For heavy users on Business plans, the recommended setup is a Codex-only seat rather than a Standard seat — it removes the rate limit ceiling and provides cleaner usage attribution.
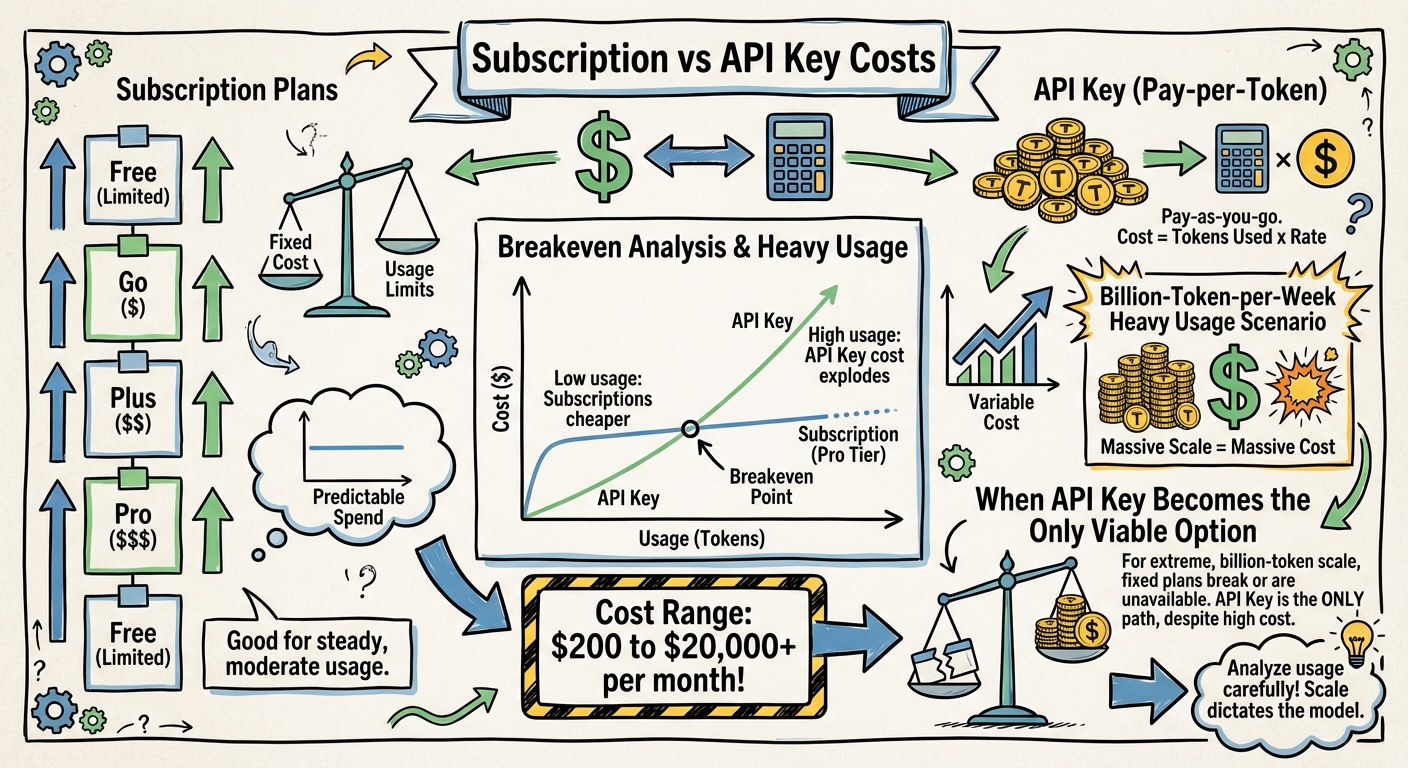
The Breakeven Analysis
At what monthly volume does each billing path make sense?
| Monthly Volume | Best Option | Monthly Cost | Why |
|---|---|---|---|
| < 48M tokens | Plus ($20) | $20 | Subscription ceiling not reached |
| 48M-240M | Pro 5× ($100) | $100 | Subscription cheaper than API |
| 240M-960M | Pro 20× ($200) | $200 | Still under ceiling, massive subsidy |
| 960M-2B | API (mini) | $1,100-2,200 | Past all subscription ceilings |
| 2B-4.3B (1B/week) | API (mini) or blended | $4,500-7,000 | Model selection is the lever |
| 4.3B+ | API (nano/batch) | Varies | Batch API and nano for cost control |
The crossover point is ~960M tokens/month. Below that, Pro 20× at $200/month is the most subsidised deal in AI — effectively $0.21 per million tokens, compared to $0.75-2.50 on the API. Above that, you have no choice but the API, and model selection becomes the primary cost control.
The Hidden Cost: Cache Efficiency
The calculations above assume a 70% cache hit rate on input tokens. This number is not guaranteed — it depends on how you use Codex CLI:
| Usage Pattern | Typical Cache Hit Rate | Impact on Weekly Cost (5.4-mini) |
|---|---|---|
| Long continuous sessions (30+ min) | 75-85% | $980-1,050 |
| Short sessions, same codebase | 60-70% | $1,100-1,200 |
| Frequent context switches | 30-50% | $1,300-1,500 |
| Cold starts (new repos, CI/CD) | 5-15% | $1,600-1,800 |
The difference between best-case and worst-case caching is ~$800/week (~$3,200/month) on GPT-5.4-mini alone. For GPT-5.4, the gap widens to ~$2,400/week (~$9,600/month).
Maximising cache hits is the second most impactful cost lever after model selection:
- Use long sessions rather than many short ones
- Keep the same codebase context across prompts within a session
- Use profiles to avoid switching models mid-session (model switches invalidate the cache)
- Avoid
--no-cacheunless debugging
Recommendations by Usage Tier
Light user (~2M tokens/week, ~$10/month API): Plus at $20/month. The subscription is more expensive than API would be, but the simplicity and included ChatGPT access make it worthwhile. You will rarely hit rate limits.
Medium user (~10M tokens/week, ~$45/month API): Plus at $20/month — you are getting a 56% subsidy versus API rates. You may occasionally hit 5-hour window limits on heavy days; Pro 5× ($100) eliminates that risk but costs more than API would.
Heavy individual (~50M tokens/week, ~$225/month API): Pro 20× at $200/month is still slightly cheaper than API and provides enough headroom. If you hit limits regularly, switch to API key with GPT-5.4-mini default — expected cost ~$225/month with no rate limits.
Extreme individual (~300M tokens/week, ~$1,350/month API): API key is the only option. Pro 20× caps out around 240M tokens/week. Use a blended model strategy (70% mini, 25% full, 5% nano) to keep costs around $930/month instead of $1,350.
Team of 10 medium users (~100M tokens/week, ~$450/month API): Codex-only seats on ChatGPT Business. Same API rates but with admin spend controls, per-user monitoring, and centralised billing. Expected cost: ~$450/month for the team.
Team of 50 with CI/CD (~1B tokens/week): Codex-only seats plus Batch API for non-interactive pipelines. Interactive developer usage at mini rates: ~$2,250/month. CI/CD pipelines on batch: ~$2,244/month. Total: ~$4,500/month — far less than 50 × $200 Pro subscriptions ($10,000).
Batch-heavy workflow (CI/CD, code review pipelines): Use the Batch API for all non-interactive work. At 1B tokens/week on GPT-5.4-mini batch: $2,244/month — less than half the standard rate.
Key Takeaways
- Real-world data: 90% of developers consume under $12/day (~5M tokens/week). The average is $6/day. Truly heavy individual usage peaks around 300M tokens/week — not billions46.
- One billion tokens/week is a team number, not an individual one — achievable by 50 developers plus CI/CD automation, not by a single person at a keyboard.
- Subscription plans are massively subsidised: effective rates of $0.21-0.42 per million tokens, versus $0.75-15.00 on the API. But the subsidy comes with hard volume ceilings.
- The crossover point is ~240M tokens/month (~60M/week). Below that, Pro 20× at $200/month beats API rates. Above it, the API key is the only option.
- Model selection is the largest cost lever: GPT-5.4-mini at 30% of GPT-5.4’s cost handles 70-80% of tasks. A blended strategy saves 54%.
- 60-80% of tokens in agentic sessions are waste — spent on context re-reading and retries, not writing code5. Reducing waste is as impactful as choosing a cheaper model.
- Cache hit rate is the second largest lever: the difference between 80% and 15% cache hits is ~$3,200/month on GPT-5.4-mini at team volume.
- Codex-only seats on ChatGPT Business provide API-rate billing with enterprise admin controls — the recommended path for teams.
- The Batch API halves costs for non-interactive workloads — $2,244/month for 1B tokens/week on GPT-5.4-mini.
Citations
-
Codex Pricing — OpenAI Developers. Subscription tiers, usage limits per 5-hour window, Pro 5×/20× multipliers, promotional boosts. https://developers.openai.com/codex/pricing ↩ ↩2 ↩3
-
OpenAI API Pricing — Per-million-token rates for GPT-5.4, GPT-5.4-mini, GPT-5.4-nano, GPT-5.3-Codex including Standard, Batch, Flex, and Priority tiers. https://developers.openai.com/api/docs/pricing ↩ ↩2 ↩3 ↩4
-
Why Is My Codex CLI Token Usage Suddenly So High? — BSWEN (March 2026). Median context per turn (~96K), p95 (~200K), startup overhead (21-22K), shell output share (90.3%), community reports of single-prompt quota consumption. https://docs.bswen.com/blog/2026-03-02-codex-cli-token-usage-spike/ ↩ ↩2 ↩3 ↩4 ↩5
-
Claude Code Token Limits: A Guide for Engineering Leaders — Faros.ai. Anthropic-published average of $6/developer/day, 90% under $12/day, session token allocations by plan tier. https://www.faros.ai/blog/claude-code-token-limits ↩ ↩2 ↩3 ↩4
-
The Real Cost of AI Coding in 2026 — Morph. Agent session costs ($6-8 baseline), 60-80% token waste rates, $500-2,000/month for heavy API users, 47-iteration agent loop case study. https://www.morphllm.com/ai-coding-costs ↩ ↩2 ↩3 ↩4 ↩5
-
Claude Code Pricing 2026: Plans, Token Costs, and Real Usage Estimates — Verdent Guides. Usage tiers (light $2-5/day, medium $6-12/day, heavy $20-60+/day), extreme user case study (10B tokens / 8 months = ~312M tokens/week). https://www.verdent.ai/guides/claude-code-pricing-2026 ↩ ↩2 ↩3 ↩4 ↩5
-
Codex Usage After the Limit Reset Update — OpenAI Developer Community. Single prompt eating 7% of weekly limits, 97% weekly allowance after three prompts. https://community.openai.com/t/codex-usage-after-the-limit-reset-update-single-prompt-eats-7-of-weekly-limits-plus-tier/1365284 ↩
-
Codex CLI Model Selection and Cost Optimisation — Profile-based model switching, prefix caching economics, and cache hit rate impact on effective costs. https://codex.danielvaughan.com/2026/03/26/codex-cli-model-selection/ ↩ ↩2
-
Codex Rate Card — OpenAI Help Center. Codex-only seat billing model, token consumption rates, Standard vs Codex-only seat comparison. https://help.openai.com/en/articles/20001106-codex-rate-card ↩ ↩2 ↩3
-
Managing Credits and Spend Controls in ChatGPT Business — OpenAI Help Center. Admin controls for per-user and per-seat-type credit limits, usage monitoring dashboard. https://help.openai.com/en/articles/20001155-managing-credits-and-spend-controls-in-chatgpt-business ↩ ↩2 ↩3