Model Routing and Advisor Patterns: How to Cut AI Coding Costs Without Losing Quality
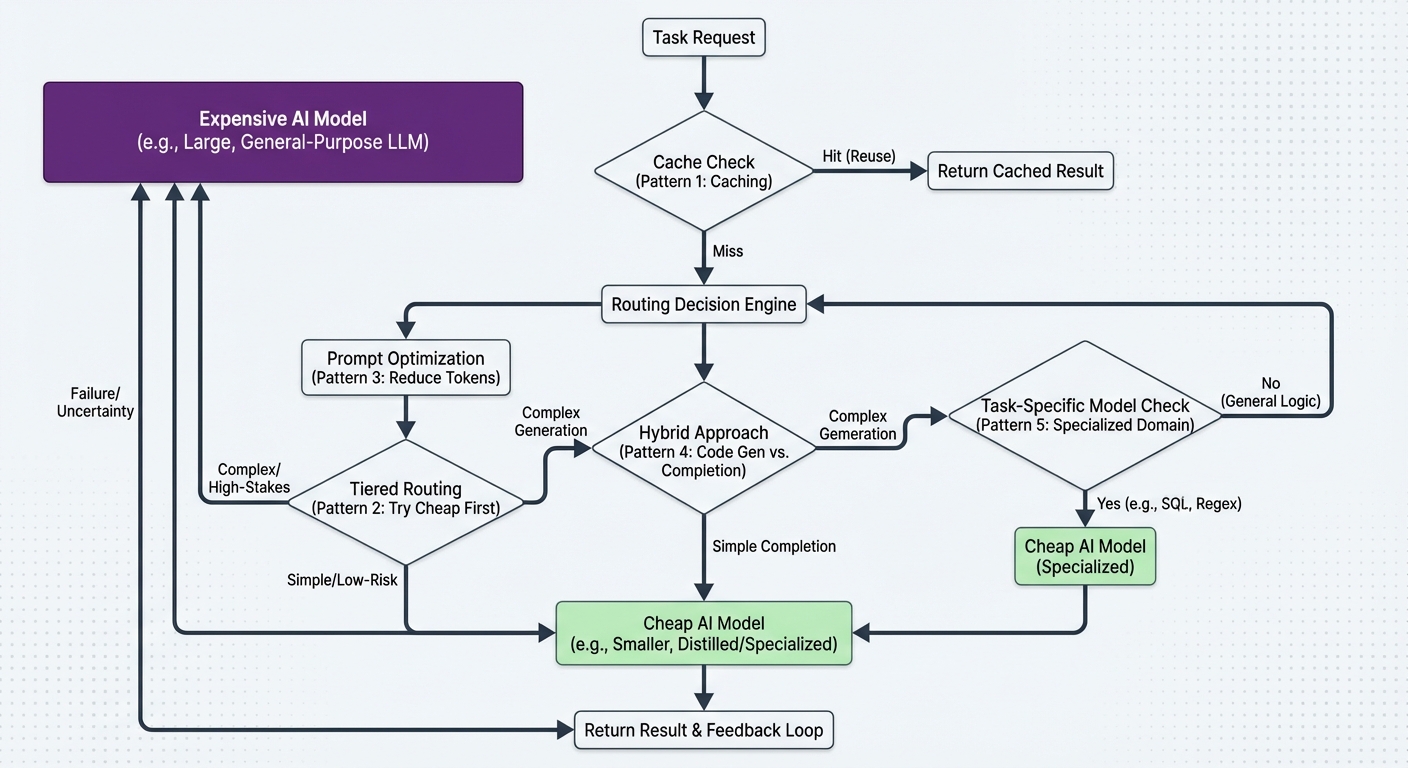
Running your most powerful model on every task is the fastest way to burn through your API budget. A one-line grep does not need GPT-5.4 or Opus 4.6. A complex architectural refactor probably does. The challenge is routing the right task to the right model automatically, without manual switching.
Three distinct patterns have emerged in April 2026 for solving this across the major AI coding CLIs. Each takes a different approach, but the goal is identical: flagship intelligence when it matters, cheaper models when it does not.
Pattern 1: Anthropic’s Advisor Strategy (Claude API)
Anthropic shipped the Advisor Strategy on April 9, 2026 as a public beta on the Claude Platform API1. The concept: a cheaper executor model (Sonnet 4.6 or Haiku 4.5) runs the task end-to-end. When it hits a decision it cannot confidently make, it consults Opus 4.6 as an advisor. Opus reviews the shared context, returns a plan or correction, and the executor resumes.
Implementation is a single addition to a Messages API call. Add the advisor tool with type advisor_20250301, set a max_uses cap to control costs, and the routing happens inside the conversation turn2.
The benchmark results are strong. Sonnet with an Opus advisor scored 2.7 percentage points higher on SWE-bench Multilingual than Sonnet solo, while costing 11.9% less per task. Haiku’s BrowseComp score more than doubled — from 19.7% to 41.2% — with Opus advising1. For a typical 25-turn coding agent with three advisor consultations, Sonnet + Opus advisor costs roughly 73% less than running Opus end-to-end2.
The limitation: this is a Claude API feature. It works in custom agent builds using the Messages API, but Claude Code itself does not expose advisor routing through its CLI interface yet.
Pattern 2: Codex CLI Profile-Based Routing
Codex CLI takes a different approach. Instead of in-conversation escalation, it uses configuration profiles that let you switch models based on task type3.
[profiles.fast]
model = "gpt-4o-mini"
approval_policy = "never"
model_reasoning_effort = "low"
[profiles.reasoning]
model = "o3"
approval_policy = "on-failure"
model_reasoning_effort = "high"
Run codex --profile fast for quick edits, file generation, and low-stakes tasks. Switch to codex --profile reasoning when you need deeper analysis. GPT-5.4-mini uses only 30% of the GPT-5.4 quota, so routine work consumes significantly less of your allowance4.
This is manual routing — you decide which profile to use. But it integrates with Codex CLI’s subagent architecture to create something closer to automatic escalation. When a GPT-5.4 parent agent spawns GPT-5.4-mini subagents for parallel subtasks, you get the advisor pattern in reverse: the expensive model plans, the cheap models execute5.
The subagent approach shipped on March 16, 2026 and works natively in Codex CLI without additional tooling.
Pattern 3: Oh My Codex (OMX) Task-Complexity Routing
Oh My Codex (OMX) is an open-source orchestration layer built on top of Codex CLI that adds automatic model routing by task complexity6.
npm install -g oh-my-codex
omx setup
OMX wraps Codex with 33 specialised agent prompts organised into build, analysis, review, and coordination lanes. Its model routing assigns simpler tasks to cheaper models and escalates to more capable models for complex work — similar in spirit to the Advisor Strategy but operating at the task level rather than within a single conversation.
Advanced configurations support mixed-provider teams via OMX_TEAM_WORKER_CLI_MAP, meaning you can route some tasks to Codex and others to Claude Code based on what each handles best6.
Pattern 4: LiteLLM Gateway Routing
For teams that want full control over model routing across multiple providers, LiteLLM provides a proxy gateway that sits between Codex CLI and any model provider3:
# litellm_config.yaml
model_list:
- model_name: "fast"
litellm_params:
model: "gpt-4o-mini"
- model_name: "reasoning"
litellm_params:
model: "o3"
- model_name: "claude"
litellm_params:
model: "claude-sonnet-4-6"
This supports OpenAI, Anthropic, Google, Azure, OpenRouter, and others through a single configuration file. Codex CLI connects to localhost:4000 and the gateway handles model name mapping, header injection, and parameter filtering. You can even route Codex CLI to Claude models via this setup3.
Pattern 5: The 4-Tier CLAUDE.md Approach
A community pattern gaining traction encodes routing rules directly in the agent’s configuration file7. The approach defines four tiers:
| Tier | Model | Use case |
|---|---|---|
| 0 | Local 7B (Ollama) | Classification, routing, summarisation |
| 1 | Haiku | Structured outputs requiring API reliability |
| 2 | Sonnet | Multi-step reasoning, code generation |
| 3 | Opus | Irreversible actions, highest-stakes decisions |
The key rule: every task starts at the cheapest tier that can handle it correctly. Background operations default to Tier 0 and only escalate when output fails validation. The author reports ~95% reduction in API spend for background agent work7.
This pattern is Claude Code-specific (rules go in CLAUDE.md), but the same logic could be encoded in Codex CLI’s AGENTS.md or codex.toml instructions to achieve similar routing behaviour.
Codex CLI: What Works Today
For Codex CLI users specifically, the practical options as of April 2026 are:
- Profile switching — built-in, zero setup, manual but effective
- GPT-5.4 + GPT-5.4-mini subagents — automatic, native, the closest to Advisor Strategy
- OMX orchestration — automatic routing by task complexity, requires additional tooling
- LiteLLM gateway — maximum flexibility, cross-provider, requires proxy setup
- AGENTS.md routing rules — encode tier logic in project instructions, relies on model compliance
The subagent pattern is the most interesting for Codex CLI users because it requires no external tooling. A GPT-5.4 parent agent that delegates parallelisable subtasks to GPT-5.4-mini workers is architecturally equivalent to the Advisor Strategy running in reverse — expensive model advises, cheap models execute — and it ships with Codex CLI out of the box.
The Cost Case
The numbers make the case for model routing regardless of which CLI you use. Running Opus end-to-end on a 25-turn agent session costs roughly 3.7× more than Sonnet + Opus advisor2. Running GPT-5.4 on every Codex CLI task uses 3.3× more quota than mixing in GPT-5.4-mini for routine work4. The quality difference on straightforward tasks is negligible.
The pattern is converging across providers: use the expensive model for planning and critical decisions, the cheap model for execution and routine work. The implementation details differ — API-level advisor tools, CLI profiles, orchestration layers, configuration-file routing — but the economics are the same everywhere.
Citations
-
Anthropic, The Advisor Strategy: Give Sonnet an Intelligence Boost with Opus, April 9, 2026. SWE-bench Multilingual and BrowseComp benchmark results. ↩ ↩2
-
Anthropic, Advisor Tool — Claude API Docs. Implementation details, cost estimates, public beta header
advisor-tool-2026-03-01. ↩ ↩2 ↩3 -
DeepWiki, Model Provider Routing — feiskyer/codex-settings. LiteLLM gateway architecture, profile-based configuration, supported providers. ↩ ↩2 ↩3
-
OpenAI, Models — Codex. GPT-5.4-mini quota consumption at 30% of GPT-5.4 rate. ↩ ↩2
-
OpenAI, Features — Codex CLI. Subagent support shipped March 16, 2026. ↩
-
a2a-mcp.org, What Is Oh My Codex (OMX)?. Open-source orchestration layer, task-complexity routing, mixed-provider teams. ↩ ↩2
-
DEV Community, Claude Code Is Burning Your API Budget: The Model Routing Architecture That Fixes It. 4-tier routing pattern, ~95% background cost reduction. ↩ ↩2