From Codex to GPT-5.4: The Complete History of OpenAI's Code Models
From Codex to GPT-5.4: The Complete History of OpenAI’s Code Models
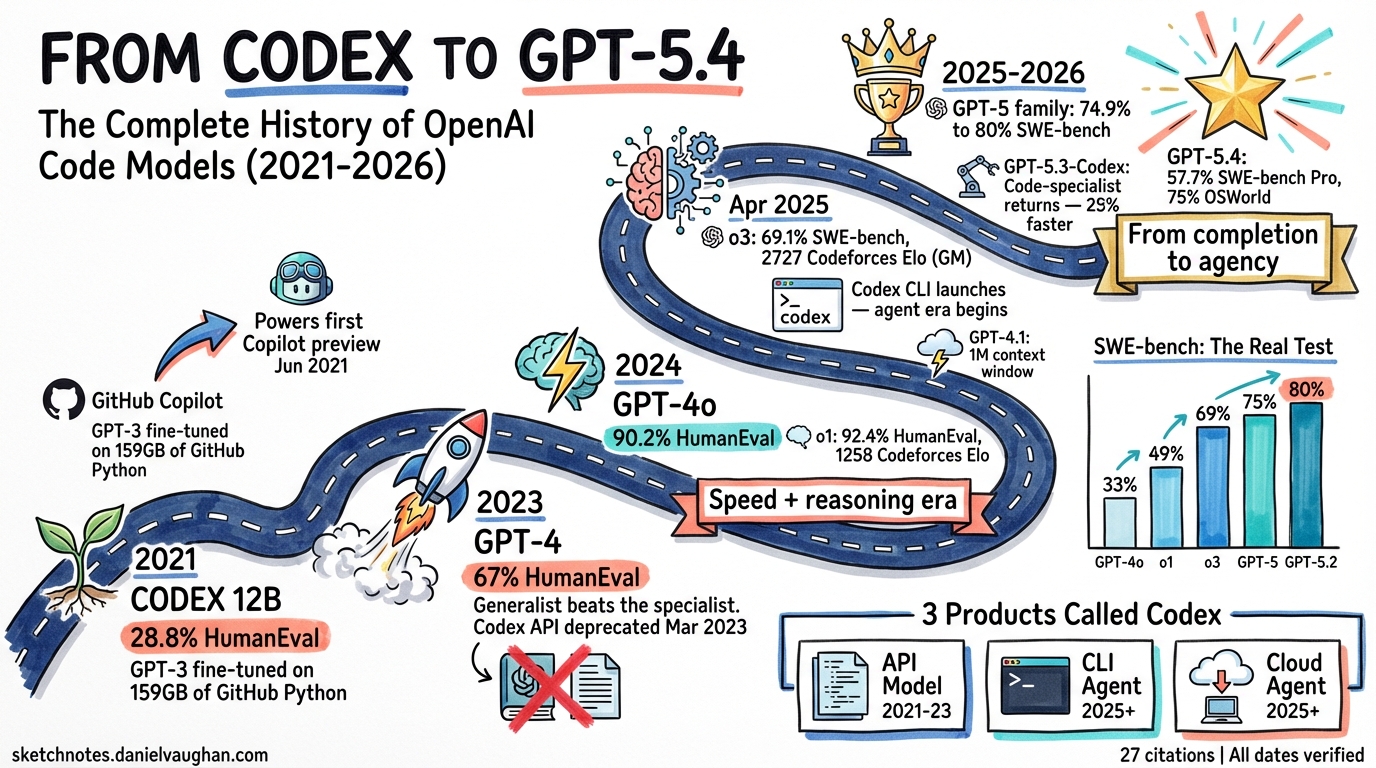
In July 2021, OpenAI published a paper describing a GPT-3 model fine-tuned on 159 gigabytes of Python code from 54 million GitHub repositories1. They called it Codex. It scored 28.8% on the HumanEval benchmark — a new test of 164 hand-written programming problems. Five years later, GPT-5.4 scores roughly 95%+ on the same benchmark and resolves 57.7% of real-world GitHub issues autonomously on SWE-bench Pro2. The name “Codex” has returned — not as a model, but as an autonomous coding agent.
This article traces every step of that journey: exact release dates, benchmark scores, architectural shifts, pricing changes, and the models that powered GitHub Copilot at each stage.
The Complete Timeline
Phase 1: The Original Codex (2021–2023)
| Date | Model / Event | What Changed |
|---|---|---|
| 29 Jun 2021 | GitHub Copilot technical preview | First public use of Codex — inline code suggestions in VS Code3 |
| Jul 2021 | Codex paper published | arXiv:2107.03374. GPT-3 (12B params) fine-tuned on GitHub code. Introduced HumanEval benchmark. 28.8% pass@11 |
| 10 Aug 2021 | Codex API (private beta) | code-cushman-001 (~2.5B params) and code-davinci-001 available via API4 |
| 2022 | code-davinci-002 | Improved variant. Larger context, better instruction following. Became the foundation for GPT-3.55 |
| 30 Nov 2022 | ChatGPT launched (GPT-3.5) | Conversational coding via chat. GPT-3.5 descended directly from code-davinci-0025 |
| 1 Mar 2023 | GPT-3.5-turbo API | 10× cheaper than text-davinci-003. OpenAI’s recommended Codex replacement6 |
| 23 Mar 2023 | Codex API deprecated | code-davinci-002 and code-cushman-001 shut down. End of the original Codex era6 |
What Codex proved: A general-purpose language model, fine-tuned on code, could generate working programs from natural language descriptions. The 28.8% HumanEval score seems modest now, but it was the first time any model could solve nearly a third of novel programming problems on its first attempt.
Phase 2: The GPT-4 Era (2023–2024)
| Date | Model / Event | What Changed |
|---|---|---|
| 14 Mar 2023 | GPT-4 | Major quality leap. 67.0% HumanEval (0-shot). Multi-step reasoning about code logic, fewer hallucinated APIs7 |
| 6 Nov 2023 | GPT-4 Turbo (preview) | 128K context window — fit entire codebases. JSON mode, parallel function calling8 |
| Nov 2023 | Copilot Chat → GPT-4 | GitHub Copilot Chat upgraded from GPT-3.5 to GPT-43 |
| 9 Apr 2024 | GPT-4 Turbo (GA) | Production-ready gpt-4-turbo-2024-04-09 |
| 13 May 2024 | GPT-4o | 90.2% HumanEval. 5× faster, 50% cheaper than GPT-4 Turbo. Native multimodal — could read screenshots of errors9 |
| 18 Jul 2024 | GPT-4o mini | 87.2% HumanEval. Replaced GPT-3.5-turbo as the default small model10 |
The GPT-4 shift: Codex was a code-specialist. GPT-4 was a generalist that happened to be excellent at code. OpenAI stopped building separate code models and instead made their flagship model good enough at coding to obsolete the specialist. This strategy held until GPT-5.3-Codex in 2026.
Phase 3: Reasoning Models (2024–2025)
| Date | Model / Event | What Changed |
|---|---|---|
| 12 Sep 2024 | o1-preview & o1-mini | First “reasoning” models. o1-preview: 92.4% HumanEval, 1258 Elo on Codeforces (89th percentile)11 |
| 5 Dec 2024 | o1 (GA) | Full o1 release. 48.9% SWE-bench Verified. 1891 Codeforces Elo12 |
| 31 Jan 2025 | o3-mini | Cost-efficient reasoning. 49.3% SWE-bench Verified12 |
| 27 Feb 2025 | GPT-4.5 (research preview) | Unsupervised scaling experiment. Better conversational quality but weaker at complex reasoning than o3-mini. Later deprecated 14 Jul 202513 |
| 27 Mar 2025 | GPT-4o Copilot (code completion GA) | New code-completion model for Copilot, based on GPT-4o mini, trained on 275K+ repos across 30+ languages. Replaced the GPT-3.5-turbo-based “copilot-codex” completion model permanently14 |
| 14 Apr 2025 | GPT-4.1, GPT-4.1 mini, GPT-4.1 nano | 1M token context. GPT-4.1: 54.6% SWE-bench Verified — a 21.4% improvement over GPT-4o’s 33.2%15 |
| 16 Apr 2025 | o3 and o4-mini | o3: 69.1% SWE-bench Verified, 2727 Codeforces Elo (99th+ percentile). o4-mini: 68.1% SWE-bench Verified12 |
| 16 Apr 2025 | Codex CLI launched | Open-source terminal agent (Rust). Reads, edits, and runs code in sandboxed environments. Apache 2.0 license16 |
| 16 May 2025 | Codex cloud agent (research preview) | Autonomous cloud coding agent powered by codex-1 (o3 fine-tuned for SWE). Parallel task execution in isolated containers17 |
| 10 Jun 2025 | o3-pro | Premium reasoning tier with dedicated GPU allocation |
The reasoning shift: The o-series introduced chain-of-thought reasoning that dramatically improved performance on algorithmic problems and multi-step debugging. o3 reached 2727 Elo on Codeforces — equivalent to Candidate Master level, outperforming 99% of competitive programmers. Meanwhile, Codex CLI brought autonomous agent capabilities to the terminal for the first time.
Phase 4: GPT-5 and the Codex Revival (2025–2026)
| Date | Model / Event | What Changed |
|---|---|---|
| 7 Aug 2025 | GPT-5 | 74.9% SWE-bench Verified (with thinking). 88% Aider Polyglot. Unified reasoning architecture18 |
| 12 Nov 2025 | GPT-5.1 | 76.3% SWE-bench Verified. More steerable coding, less overthinking19 |
| 19 Nov 2025 | GPT-5.1-Codex-Max | Agentic coding variant of GPT-5.1 |
| 11 Dec 2025 | GPT-5.2 | 80.0% SWE-bench Verified. 55.6% SWE-bench Pro — state of the art at the time20 |
| 5 Feb 2026 | GPT-5.3-Codex | Return to code-specialised fine-tuning. 56.8% SWE-bench Pro. 77.3% Terminal-Bench 2.0. 25% faster on agentic tasks21 |
| 9 Feb 2026 | GPT-5.3-Codex GA in Copilot | Available to Pro, Pro+, Business, Enterprise22 |
| 5 Mar 2026 | GPT-5.4 (Thinking + Pro) | 57.7% SWE-bench Pro. ~80% SWE-bench Verified. 75% OSWorld (computer use). 1M context, 128K max output2 |
| 17 Mar 2026 | GPT-5.4 mini & GPT-5.4 nano | GPT-5.4 mini: 54.38% SWE-bench Pro. Nano: edge/embedded variant23 |
| 17 Mar 2026 | GPT-5.4 mini GA in Copilot | Available across all Copilot tiers24 |
| 18 Mar 2026 | GPT-5.3-Codex designated LTS | First long-term support model in Copilot. Guaranteed through 4 Feb 2027 for Business/Enterprise25 |
The Codex revival: After three years of the “generalist is good enough” strategy, OpenAI returned to code-specialised fine-tuning with GPT-5.3-Codex. The name was deliberate — a callback to the 2021 original, but the model was a completely different beast: an agent-optimised variant that was 25% faster on tool-driven tasks and became the first model to receive long-term support guarantees for enterprise Copilot users.
Benchmark Progression
HumanEval pass@1 (164 problems)
HumanEval measures a model’s ability to generate correct Python functions from docstrings. It was introduced alongside the original Codex paper1.
| Model | Date | HumanEval | Improvement |
|---|---|---|---|
| Codex-12B | Jul 2021 | 28.8% | Baseline |
| code-davinci-002 | 2022 | ~47% | +18pp |
| GPT-4 | Mar 2023 | 67.0% | +20pp |
| GPT-4o mini | Jul 2024 | 87.2% | +20pp |
| GPT-4o | May 2024 | 90.2% | +3pp |
| o1-preview | Sep 2024 | 92.4% | +2pp |
| Frontier (2025+) | — | 95%+ | Saturated |
HumanEval pass@1 Progression (2021-2025)
═══════════════════════════════════════════
Codex-12B (Jul 2021) ████████▉ 28.8%
code-dav-002 (2022) ██████████████▏ ~47%
GPT-4 (Mar 2023) ████████████████████▏ 67.0%
GPT-4o mini (Jul 2024) ██████████████████████████▏ 87.2%
GPT-4o (May 2024) ███████████████████████████▏ 90.2%
o1-preview (Sep 2024) ███████████████████████████▊ 92.4%
Frontier (2025+) █████████████████████████████▌ 95%+
0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100%
Note: HumanEval has been effectively saturated since mid-2025. All frontier models score above 95%, making it useless for differentiation. SWE-bench has replaced it as the primary coding benchmark26.
SWE-bench Verified (500 real GitHub issues)
SWE-bench Verified measures a model’s ability to autonomously resolve real software engineering issues from popular open-source repositories — a far harder test than HumanEval27.
| Model | Date | SWE-bench Verified | Improvement |
|---|---|---|---|
| GPT-4o | Nov 2024 | 33.2% | Baseline |
| o1 | Dec 2024 | 48.9% | +15.7pp |
| o3-mini | Jan 2025 | 49.3% | +0.4pp |
| GPT-4.1 | Apr 2025 | 54.6% | +5.3pp |
| o4-mini | Apr 2025 | 68.1% | +13.5pp |
| o3 | Apr 2025 | 69.1% | +1.0pp |
| GPT-5 | Aug 2025 | 74.9% | +5.8pp |
| GPT-5.1 | Nov 2025 | 76.3% | +1.4pp |
| GPT-5.2 | Dec 2025 | 80.0% | +3.7pp |
| GPT-5.4 | Mar 2026 | ~80% | ≈0pp |
SWE-bench Verified Progression (2024-2026)
═══════════════════════════════════════════
GPT-4o (Nov 2024) ████████▎ 33.2%
o1 (Dec 2024) ████████████▏ 48.9%
o3-mini (Jan 2025) ████████████▎ 49.3%
GPT-4.1 (Apr 2025) █████████████▋ 54.6%
o4-mini (Apr 2025) █████████████████ 68.1%
o3 (Apr 2025) █████████████████▎ 69.1%
GPT-5 (Aug 2025) ██████████████████▊ 74.9%
GPT-5.1 (Nov 2025) ███████████████████ 76.3%
GPT-5.2 (Dec 2025) ████████████████████ 80.0%
GPT-5.4 (Mar 2026) ████████████████████ ~80%
0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100%
SWE-bench Pro
SWE-bench Pro is a harder variant with more complex, multi-file issues. It emerged in late 2025 as the new frontier benchmark:
| Model | Date | SWE-bench Pro |
|---|---|---|
| GPT-5.2 | Dec 2025 | 55.6% |
| GPT-5.3-Codex | Feb 2026 | 56.8% |
| GPT-5.4 | Mar 2026 | 57.7% |
| GPT-5.4 mini | Mar 2026 | 54.38% |
Codeforces Elo
Competitive programming performance, measured by Elo rating on Codeforces problems:
| Model | Date | Elo | Equivalent Rank |
|---|---|---|---|
| o1-preview | Sep 2024 | 1258 | Expert (89th percentile) |
| o1 | Dec 2024 | 1891 | Candidate Master |
| o3 | Apr 2025 | 2727 | Grandmaster (99th+ percentile) |
Codeforces Elo Progression
══════════════════════════
o1-preview (Sep 2024) ███████████████░░░░░░░░░░░░░░░░ 1258 (89th %ile)
o1 (Dec 2024) ██████████████████████░░░░░░░░░ 1891 (CM)
o3 (Apr 2025) █████████████████████████████████ 2727 (GM, 99th+)
0 500 1000 1500 2000 2500 3000
GitHub Copilot: Which Model, When?
GitHub Copilot has cycled through multiple models since launch. Critically, Copilot uses different models for different features — code completion (inline suggestions) and chat (conversational coding) run on separate models:
Code Completion Model
| Period | Model | Notes |
|---|---|---|
| Jun 2021 – Mar 2023 | Codex (production variant) | Original Copilot. Code-specific model3 |
| Mar 2023 – Mar 2025 | GPT-3.5-turbo (“copilot-codex”) | After Codex API deprecation614 |
| Mar 2025 → | GPT-4o Copilot | New model trained on 275K+ repos, 30+ languages. GA 27 March 202514 |
Chat / Agent Model
| Period | Model | Notes |
|---|---|---|
| 2023 | GPT-3.5-turbo | Original Copilot Chat |
| Nov 2023 | GPT-4 | Copilot Chat upgrade3 |
| 2024 | GPT-4 Turbo → GPT-4o | Iterative upgrades; multi-model selection introduced |
| Late 2025 | Multi-model (GPT-5.1, Claude, Gemini) | 50+ updates in Nov 20253 |
| Feb 2026 | GPT-5.3-Codex (GA) | Code-specialised, 25% faster on agentic tasks22 |
| Mar 2026 | GPT-5.4 mini added | Available across all tiers24 |
| Mar 2026 | GPT-5.3-Codex designated LTS | First LTS model. Guaranteed through 4 Feb 202725 |
The LTS designation for GPT-5.3-Codex is significant — it is the first time GitHub has promised a specific model version will remain available for a fixed period, giving enterprises deployment stability.
Three Products Called “Codex”
The name “Codex” has been applied to three distinct products. Understanding the difference matters:
Codex v1: The API Model (2021–2023)
A GPT-3 fine-tuned on code. You sent a prompt, you got code back. No agency — pure completion. Deprecated March 20236.
Codex v2: The CLI Agent (April 2025–present)
An open-source, Rust-built terminal agent16. It reads your repository, plans changes, edits files, runs commands, and iterates — all inside a sandboxed environment. It is not a model; it is an agent that uses models (currently GPT-5.4, GPT-5.4-mini, GPT-5.3-Codex). Install via npm i -g @openai/codex.
Codex v3: The Cloud Agent (May 2025–present)
An autonomous cloud coding agent powered by codex-1 (o3 fine-tuned for software engineering)17. Runs in OpenAI’s cloud infrastructure in isolated containers. Handles longer-horizon tasks than the CLI — full feature implementation, multi-file refactoring, test generation. Available to ChatGPT Pro, Business, and Enterprise users.
The Pricing Journey
Model pricing has decreased dramatically per unit of capability:
| Model | Date | Input / Output (per M tokens) | Relative to Codex-12B |
|---|---|---|---|
| Codex (davinci) | 2021 | $0.10 / $0.10 (estimated) | Baseline |
| GPT-3.5-turbo | Mar 2023 | $0.002 / $0.002 | ~50× cheaper |
| GPT-4 | Mar 2023 | $0.03 / $0.06 | Similar (but far more capable) |
| GPT-4o | May 2024 | $0.005 / $0.015 | 6× cheaper than GPT-4 |
| GPT-4o mini | Jul 2024 | $0.00015 / $0.0006 | 100× cheaper than GPT-4 |
| GPT-4.1 | Apr 2025 | $0.002 / $0.008 | Cheaper than original Codex |
| GPT-5.4 | Mar 2026 | $2.50 / $15.00 | Premium frontier |
| GPT-5.4-mini | Mar 2026 | $0.75 / $4.50 | Sweet spot |
| GPT-5.4-nano | Mar 2026 | $0.20 / $1.25 | Budget |
| GPT-5.3-Codex | Feb 2026 | $1.75 / $14.00 | Code-specialised value |
What Changed and What Stayed the Same
What changed
- Scale: 12B parameters (2021) → undisclosed but vastly larger (2026)
- Architecture: Pure completion → instruction-tuned → reasoning chains → autonomous agents
- Context: 2K tokens (2021) → 1M tokens (2026) — a 500× increase
- Benchmark performance: 28.8% HumanEval → 57.7% SWE-bench Pro (a fundamentally harder test)
- Interaction model: “Give me code” → “Fix this issue, test it, and open a PR”
- Delivery: API-only → CLI agent → cloud agent → embedded in IDE
What stayed the same
- The core insight: pre-training on vast quantities of code produces emergent programming capability
- The name “Codex” — deliberately revived in 2025 as a brand for OpenAI’s coding tools
- GitHub Copilot as the primary consumer-facing product
- The competitive pressure: Copilot’s model choices are driven by benchmarks, speed, and cost relative to Claude, Gemini, and the open-source ecosystem
The Trajectory
The five-year progression tells a clear story:
- 2021–2022: Prove that code generation works (Codex)
- 2023: Subsume code into general intelligence (GPT-4)
- 2024: Make it fast and cheap (GPT-4o, GPT-4o mini)
- 2024–2025: Add reasoning (o1, o3)
- 2025: Give it agency (Codex CLI, Codex cloud)
- 2026: Return to specialisation (GPT-5.3-Codex) while pushing the frontier (GPT-5.4)
The next chapter is already being written. GPT-5.4’s 75% on OSWorld — a benchmark for computer use, not just coding — suggests that the boundary between “code model” and “general agent” is dissolving entirely. The Codex of 2026 does not just write code. It reads documentation, navigates APIs, provisions infrastructure, and reviews its own work.
From 28.8% to 57.7%. From completion to agency. From a research paper to a product that processes 78 Azure CLI issues in a single day.
That is the history of Codex.
Citations
-
Evaluating Large Language Models Trained on Code — Chen et al., OpenAI (July 2021). Introduced Codex (12B params, 28.8% HumanEval) and the HumanEval benchmark. https://arxiv.org/abs/2107.03374 ↩ ↩2 ↩3
-
Introducing GPT-5.4 — OpenAI (March 2026). 57.7% SWE-bench Pro, ~80% SWE-bench Verified, 75% OSWorld. https://openai.com/index/introducing-gpt-5-4/ ↩ ↩2
-
GitHub Copilot — Wikipedia. Timeline of Copilot launches, model transitions, and feature additions. https://en.wikipedia.org/wiki/GitHub_Copilot ↩ ↩2 ↩3 ↩4 ↩5
-
OpenAI Announces Codex — InfoQ (August 2021). API private beta launch details. https://www.infoq.com/news/2021/08/openai-codex/ ↩
-
OpenAI Model Deprecations — code-davinci-002 as foundation for GPT-3.5 series. https://platform.openai.com/docs/deprecations ↩ ↩2
-
Codex API Deprecated — OpenAI (March 2023). code-davinci-002 and code-cushman-001 shut down; GPT-3.5-turbo recommended as replacement. https://platform.openai.com/docs/deprecations ↩ ↩2 ↩3 ↩4
-
GPT-4 Technical Report — OpenAI (March 2023). 67.0% HumanEval (0-shot). https://arxiv.org/html/2303.08774v6 ↩
-
New Models and Developer Products Announced at DevDay — OpenAI (November 2023). GPT-4 Turbo, 128K context. https://openai.com/index/new-models-and-developer-products-announced-at-devday/ ↩
-
GPT-4o Review — TextCortex. 90.2% HumanEval, 5× faster than GPT-4 Turbo. https://textcortex.com/post/gpt-4o-review ↩
-
GPT-4o mini: Advancing Cost-Efficient Intelligence — OpenAI (July 2024). 87.2% HumanEval. https://openai.com/index/gpt-4o-mini-advancing-cost-efficient-intelligence/ ↩
-
Introducing OpenAI o1-preview — OpenAI (September 2024). 92.4% HumanEval, 1258 Codeforces Elo. https://openai.com/index/introducing-openai-o1-preview/ ↩
-
Introducing o3 and o4-mini — OpenAI (April 2025). o3: 69.1% SWE-bench Verified, 2727 Codeforces Elo. o4-mini: 68.1% SWE-bench. o1: 48.9%, o3-mini: 49.3%. https://openai.com/index/introducing-o3-and-o4-mini/ ↩ ↩2 ↩3
-
GPT-4.5 System Card — OpenAI (February 2025). https://cdn.openai.com/gpt-4-5-system-card-2272025.pdf ↩
-
GPT-4o Copilot: Your New Code Completion Model — GitHub Changelog (March 2025). Trained on 275K+ repos, 30+ languages. Replaced copilot-codex permanently. https://github.blog/changelog/2025-03-27-gpt-4o-copilot-your-new-code-completion-model-is-now-generally-available/ ↩ ↩2 ↩3
-
GPT-4.1 — OpenAI (April 2025). 54.6% SWE-bench Verified, 1M context. https://openai.com/index/gpt-4-1/ ↩
-
Codex CLI — OpenAI GitHub Repository. Open-source terminal coding agent, Apache 2.0. https://github.com/openai/codex ↩ ↩2
-
Introducing Codex — OpenAI (May 2025). Cloud-based coding agent powered by codex-1. https://openai.com/index/introducing-codex/ ↩ ↩2
-
Introducing GPT-5 — OpenAI (August 2025). 74.9% SWE-bench Verified, 88% Aider Polyglot. https://openai.com/index/introducing-gpt-5/ ↩
-
Introducing GPT-5.1 — OpenAI (November 2025). 76.3% SWE-bench Verified. https://openai.com/index/gpt-5-1/ ↩
-
Introducing GPT-5.2 — OpenAI (December 2025). 80.0% SWE-bench Verified, 55.6% SWE-bench Pro. https://openai.com/index/introducing-gpt-5-2/ ↩
-
Introducing GPT-5.3-Codex — OpenAI (February 2026). 56.8% SWE-bench Pro, 77.3% Terminal-Bench 2.0, 25% faster. https://openai.com/index/introducing-gpt-5-3-codex/ ↩
-
GPT-5.3-Codex Is Now Generally Available for GitHub Copilot — GitHub Changelog (February 2026). https://github.blog/changelog/2026-02-09-gpt-5-3-codex-is-now-generally-available-for-github-copilot/ ↩ ↩2
-
GPT-5.4 mini and nano — OpenAI (March 2026). GPT-5.4 mini: 54.38% SWE-bench Pro. https://openai.com/index/introducing-gpt-5-4-mini-and-nano/ ↩
-
GPT-5.4 mini Is Now Generally Available for GitHub Copilot — GitHub Changelog (March 2026). https://github.blog/changelog/2026-03-17-gpt-5-4-mini-is-now-generally-available-for-github-copilot/ ↩ ↩2
-
GPT-5.3-Codex Long-Term Support in GitHub Copilot — GitHub Changelog (March 2026). Guaranteed through 4 Feb 2027. https://github.blog/changelog/2026-03-18-gpt-5-3-codex-long-term-support-in-github-copilot/ ↩ ↩2
-
AI Coding Benchmarks 2026 — Morphllm. HumanEval saturation analysis, shift to SWE-bench. https://www.morphllm.com/ai-coding-benchmarks-2026 ↩
-
SWE-bench Explained — LocalAIMaster. Benchmark methodology, Verified vs Pro variants. https://localaimaster.com/models/swe-bench-explained-ai-benchmarks ↩