SAFe Was Bad for Agility. For AI Coding Agents, It's Worse.
Jeff Gothelf’s recent article “SAFe Was Bad for Agility. For AI, It’s Catastrophic” makes a sharp argument: the Scaled Agile Framework, which was already damaging for software agility, becomes actively destructive when applied to AI product development1. His reasoning applies with equal force to enterprise adoption of AI coding agents like Codex CLI — and the data emerging from the first year of serious enterprise AI coding adoption confirms it.
The SAFe Problem Is Now an AI Problem
SAFe (Scaled Agile Framework) is the dominant enterprise agile methodology, used by 30% of organisations scaling agile and growing2. It organises work into Program Increments (PIs) — typically 8-12 week planning cycles with fixed scope, predetermined features, and hierarchical decision-making. In theory, SAFe provides predictability at scale. In practice, it replaces the responsiveness that agile was supposed to deliver with the rigidity that agile was supposed to eliminate.
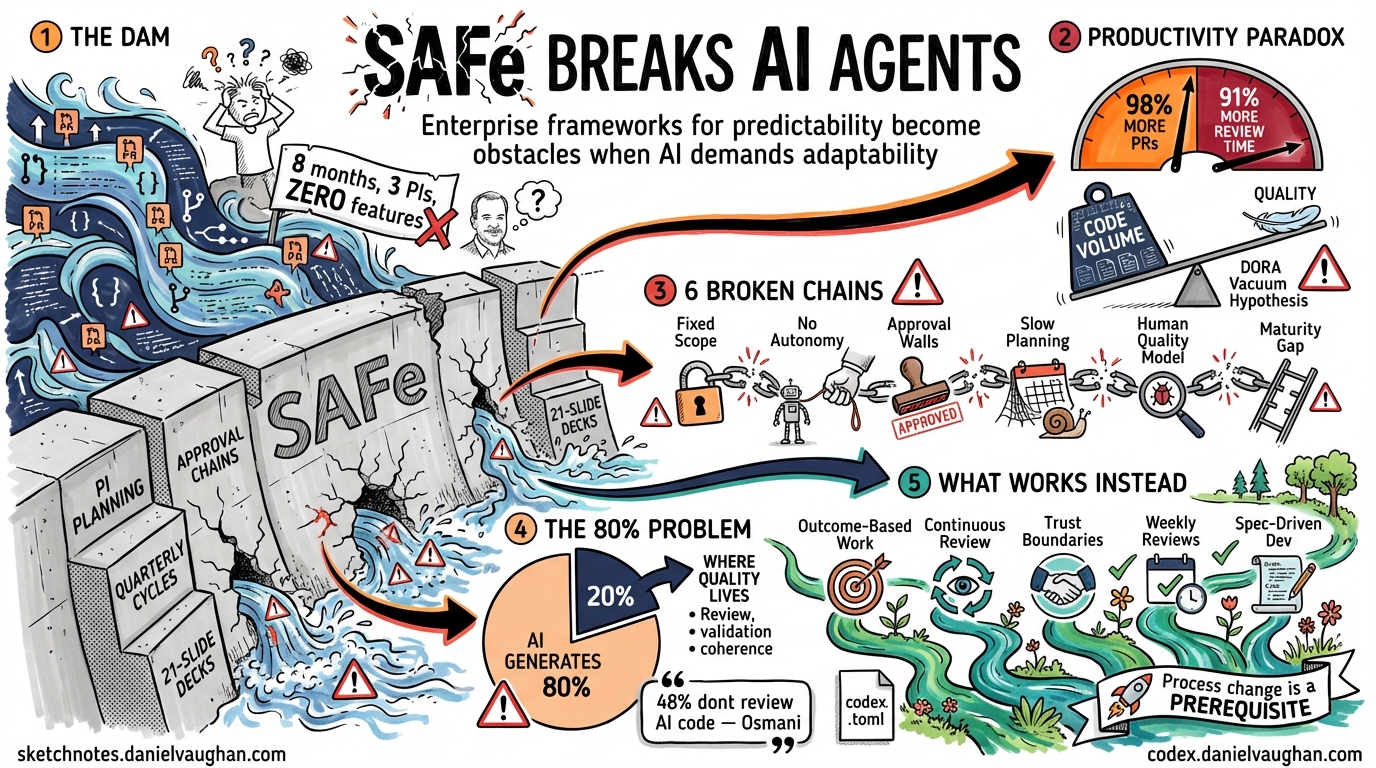
Gothelf’s concrete example is damning: an insurance company assembled a dedicated AI working group, ran three PI planning cycles with formally assigned AI use cases to Release Trains, produced a 21-slide deck explaining their AI strategy — and shipped zero AI-powered features in eight months. That, Gothelf writes, was “SAFe working exactly as designed.”1
He is not alone. The AI4Agile Practitioners Report 2026 found that while 83% of Agile practitioners now use AI tools, most spend 10% or less of their time with them — integration uncertainty is the biggest adoption barrier at 54.3%, nearly 18 percentage points ahead of any other factor3. Marty Cagan’s Silicon Valley Product Group has been making a related argument: when AI agents can build almost anything quickly, the bottleneck is no longer implementation — it is direction and learning4. SAFe optimises for implementation throughput. It has no mechanism for the discovery work that AI demands.
The Numbers That Should Alarm Enterprise Leaders
The JetBrains survey tells the tool adoption story: Claude Code has 18% work adoption, while Codex CLI — despite having a larger total user base across the Codex platform — shows only 3% work adoption5. The gap between “developers who have tried it” and “developers who use it at work” is not a product problem. It is a process problem.
But the enterprise data tells a more troubling story about what happens even when adoption succeeds:
The Productivity Paradox. Faros AI’s enterprise scaling guide found that teams with high AI adoption complete 21% more tasks and merge 98% more pull requests — but PR review time increases 91%6. The bottleneck does not disappear; it moves downstream. Google’s 2024 DORA research confirmed this at scale: 25% increased AI adoption correlated with 7.2% decreased delivery stability. Researchers called this the “Vacuum Hypothesis” — time saved generating code gets consumed by debugging and validation7.
The Security Amplifier. Apiiro research shows AI-assisted teams introduce 10× more security findings while PR volume falls by nearly a third, concentrating risk in fewer, more complex changes6. A Fortune 50 enterprise saw monthly security findings increase tenfold — from 1,000 to 10,000 — in six months7. SonarSource analysis found 48% of AI-generated code contains potential security vulnerabilities, with every major model producing high-severity issues7.
The Trust Deficit. A Writer survey found 79% of organisations face challenges in adopting AI — a double-digit increase from 2025 — with 54% of C-suite executives admitting that adopting AI is “tearing their company apart”8. Only 46% of developers trust AI tool output, and just 3% report “high trust”8. Gartner predicts over 40% of agentic AI projects will be cancelled by end of 20279.
These are not technology failures. They are process failures. The tools produce more code, but the processes cannot absorb it. SAFe’s ceremonies consume the time that should be spent on review, validation, and discovery.
Six Ways SAFe Breaks AI Coding Agent Workflows
1. Fixed Sprint Scope Kills Exploration
Codex CLI’s most powerful capability is exploratory: “Investigate this codebase and suggest an architecture for X.” An agent might discover in the first 30 minutes that the planned approach is wrong and a completely different solution is needed. In a SAFe PI, that discovery creates a change request. The change request goes to a review board. The review board meets next week. The agent sits idle.
The entire point of AI coding agents is that they compress the feedback loop between “idea” and “working code” from days to minutes. SAFe stretches it back to weeks. As Gothelf asks: when did your team last change direction based on what an AI model did in production? If the answer is “we haven’t,” it is worth asking whether SAFe is the reason1.
2. Predetermined Work Packages Prevent Agent Autonomy
SAFe decomposes work into stories, which are assigned to teams, which are scheduled into sprints. This works when humans need manageable chunks. It fails completely when an agent like Codex CLI can execute a 50-file refactor in 20 minutes that was planned as a two-sprint epic.
The agent does not care about your story point estimates. It does not respect sprint boundaries. It can do in one session what was planned for a month — but only if the process allows it to.
3. Approval Hierarchies Conflict with Agent Delegation
Codex CLI’s approval policies (auto-edit, full-auto) are designed to let agents execute without constant human intervention. SAFe’s hierarchical approval structures require human sign-off at every level. The result: teams configure Codex CLI to suggest mode (ask permission for everything), which strips the agent of its primary advantage and turns it into an expensive autocomplete tool.
The teams getting real value from Codex CLI are the ones running full-auto with guardrails (sandbox execution, git worktrees, automated tests). SAFe organisations rarely trust this approach because it bypasses the approval structures that justify the framework’s existence. Enterprises that succeed have standardised on human-in-the-loop architectures where agents execute routine decisions independently but escalate edge cases, high-stakes actions, and policy conflicts for human review6 — a model that SAFe’s hierarchical approval chains cannot express.
4. Quarterly Planning Cannot Accommodate Weekly Tool Evolution
Codex CLI shipped version 0.119 on April 10 and version 0.120 on April 11. Features that did not exist on Monday are in production by Wednesday. SAFe’s quarterly PI planning assumes a stable toolchain. When the toolchain evolves faster than the planning cycle, every PI is based on outdated assumptions about what is possible.
Teams locked into SAFe cannot adopt background agent streaming (v0.120.0), subagent parallelism, or new MCP capabilities without waiting for the next PI boundary — by which time three more versions have shipped.
5. SAFe’s Quality Model Assumes Human Authors
SAFe’s Built-in Quality relies on developer discipline, craft values, and professional pride. AI agents have none of these. Agility at Scale found that AI agents generate code at 98% higher volume while producing 1.7× more defects than human developers10. CodeRabbit data shows agents produce 2.74× more cross-site scripting vulnerabilities and 8× more performance problems. Review capacity cannot keep up: teams require 91% more review time despite the higher defect rates10.
Addy Osmani’s analysis of what he calls “comprehension debt” exposes the deeper problem: developers are merging AI-generated code they cannot explain three days later11. Code duplication has increased from 8.3% to 12.3%, while refactoring activity has collapsed from 25% to under 10%7. More code does not equal better software.
The solution is not to slow agents down — it is to replace craft-based quality with mechanically enforced governance. Harness engineering — instruction contracts, MCP servers, skills, hooks, and back-pressure mechanisms — encodes quality standards as machine-readable policy gates rather than human guidelines10. Codex CLI already supports this architecture through codex.toml profiles, sandbox constraints, and hook-based validation. SAFe’s quality model does not account for any of it.
6. The AI Maturity Gap Is a SAFe Structural Problem
An AI maturity framework for SAFe enterprises identifies four assessment dimensions: team structure fitness, delivery pipeline readiness, quality practice maturity, and AI infrastructure readiness. The critical finding: “Aggregate maturity equals the minimum of the four dimension scores” — a single weak dimension constrains overall readiness regardless of strength elsewhere12.
Most SAFe organisations score well on team structure but poorly on AI infrastructure and quality automation. The hardest transition — Level 2 (AI-Augmented, individual productivity gains) to Level 3 (AI-Integrated, organisational adaptation) — requires coordinated structural changes across all four dimensions simultaneously12. SAFe’s Release Train structure makes this coordination nearly impossible because each train optimises locally rather than systemically.
The 80% Problem and Why Process Matters More Than Tooling
Osmani describes “the 80% problem in agentic coding”: AI agents now handle 80% or more of code generation, but the remaining work — review, validation, architectural coherence — is where quality lives11. Andrej Karpathy reports moving from 80% manual coding to 80% agent coding within weeks. Boris Cherny ships 22-27 PRs daily with 100% AI-generated code11.
This works for personal projects and greenfield startups. It fails catastrophically in enterprise environments with complex invariants, regulatory requirements, and unwritten rules that agents cannot access. Osmani’s finding mirrors the Faros AI data: 48% of developers do not consistently review AI code before committing, and 38% find reviewing AI-generated code requires more effort than human-written code11.
SAFe responds to this problem by adding more ceremony — more review meetings, more sign-offs, more documentation. This is exactly wrong. The answer is not more process overhead; it is better-designed guardrails that operate at the speed of the agent, not the speed of the meeting calendar.
What Enterprise Processes Need Instead
Gothelf argues for replacing SAFe with experimentation-driven approaches for AI work. In a companion piece, “Agile in the Age of AI,” he makes the case that agile itself survives the AI era — but only if it returns to its original principles of rapid iteration and continuous learning, not the ceremonial overhead that SAFe has layered on top13. For enterprise Codex CLI adoption specifically, this translates to five structural changes:
1. Outcome-Based Work, Not Task-Based Work
Instead of “Implement story JIRA-1234: Add validation to the user form,” the work unit becomes “Reduce form submission errors by 40%.” The agent decides how to achieve the outcome. The human reviews the result, not the approach.
This maps directly to Codex CLI’s strengths. Give the agent a goal and a test suite. Let it explore solutions. Review the pull request, not the individual keystrokes. As Osmani advises: spend 70% of effort on problem definition and success criteria, 30% on execution11. GitHub’s analysis of 2,500+ agent configuration files found that teams covering all six core specification areas saw dramatically fewer post-deployment bugs14.
2. Continuous Review, Not Batch Review
Replace sprint reviews with continuous PR-based review. Codex CLI generates pull requests with explanations. Reviewers assess the PR on its merits — does it work, is it safe, does it meet standards — regardless of whether it was planned for this sprint.
This is how every high-performing Codex CLI team already works. The process needs to catch up with the tool. Faros AI’s Launch-Learn-Run framework prescribes 18+ weeks of structured rollout: 6 weeks of measurement infrastructure and pilot programs, 12 weeks of A/B testing and bottleneck analysis, then systematic scaling with business impact measurement6. This is process change that respects reality, not ceremony that denies it.
3. Trust Boundaries, Not Approval Chains
Instead of hierarchical approvals, define trust boundaries:
# codex.toml - enterprise trust configuration
[profiles.safe-refactor]
model = "gpt-5.4"
approval_policy = "auto-edit"
sandbox = true
writable_paths = ["src/", "tests/"]
[profiles.infrastructure]
model = "gpt-5.4"
approval_policy = "suggest"
writable_paths = ["infra/"]
The agent operates freely within defined boundaries. Code in src/ and tests/ gets auto-edited with sandbox protection. Infrastructure changes require human approval. The trust model is encoded in configuration, not in meeting invitations.
4. Weekly Capability Reviews, Not Quarterly Planning
Replace PI planning with weekly 30-minute capability reviews: what has the toolchain shipped this week? What new patterns are available? What experiments should we run? This keeps the team’s mental model aligned with the tool’s actual capabilities rather than the capabilities it had three months ago.
Microsoft’s research found it takes approximately 11 weeks for developers to realise full productivity benefits from AI coding tools7. Early assessments measuring week-one performance captured only partial value. A quarterly PI review cycle means the tool has already matured past three capability generations before the first assessment is complete.
5. Spec-Driven Development, Not Story-Driven Development
Osmani’s research on AI agent specifications provides the enterprise alternative to story-point-driven development14. Instead of decomposing work into stories that constrain agent autonomy, write specifications that define:
- Success criteria: what “done” looks like, expressed as testable assertions
- Constraints: what the agent must not change (databases, APIs, security boundaries)
- Context: architectural decisions, style guides, and existing patterns the agent should follow
- Verification: automated test suites that validate agent output without human review bottlenecks
This is the enterprise equivalent of Codex CLI’s AGENTS.md — institutional knowledge encoded as machine-readable instructions rather than Jira ticket descriptions.
The Role Evolution SAFe Cannot Accommodate
The shift from implementation to orchestration — what Osmani calls moving from “implementer” to “orchestrator”11 — fundamentally changes what developers do. They spend less time writing code and more time reviewing, validating, and directing agent work. This is management, not programming.
SAFe’s role structure (developers, testers, product owners, scrum masters, Release Train Engineers) does not have a role for “the person who writes specifications for AI agents and reviews their output.” Agility at Scale identifies the emerging “Harness Architect” as a staff-level specialisation where a single well-designed constraint improves thousands of lines of agent output10. SAFe has no equivalent role, no career path for it, and no ceremony that produces the artefacts it requires.
Cagan makes the broader point: feasibility risk has been significantly lowered thanks to AI coding agents, but the role of product management becomes more important, not less4. When teams can build almost anything quickly, deciding what to build and why is the only remaining competitive advantage. SAFe’s Release Trains optimise for delivery velocity. In an AI-augmented world, discovery velocity matters more.
The One Thing That Actually Works
Faros AI’s enterprise scaling research identified one factor that differentiates successful enterprise AI coding adoption from the 40% of projects that Gartner predicts will be cancelled: executive sponsorship that treats adoption as business transformation, not technology deployment6.
The EdTech case study in their research achieved 1,100% growth in AI coding adoption (25 to 300 engineers) in three months, generating $10.6M annual productivity value against $68K tool costs — a 15,324% ROI6. The key was not the tool. It was the willingness to redesign processes around the tool’s capabilities rather than constraining the tool to fit existing processes.
One enterprise governance advisor’s warning captures the stakes: “I’ve watched companies go from ‘AI is accelerating development’ to ‘we can’t ship features because we don’t understand our own systems’ in less than 18 months”7.
The Adoption Gap Is a Process Gap
The 3% work adoption figure for Codex CLI is not a ceiling imposed by the technology. It is a ceiling imposed by enterprise processes that were designed for a different era. Codex CLI can already do the work. The question is whether enterprises will redesign their processes to let it.
Gothelf’s conclusion about AI generally applies to AI coding agents specifically: frameworks built for predictability become obstacles when the work demands adaptability. SAFe gave enterprises the illusion of agility. For AI coding agents, it gives them the illusion of adoption — teams that have the tools but cannot use them because the process will not allow it.
The enterprises that succeed with Codex CLI will be the ones that treat process change as a prerequisite for tool adoption, not a follow-up task. They will replace PI planning with weekly capability reviews, story points with agent specifications, approval hierarchies with trust boundaries, and craft-based quality with harness engineering. The tools are ready. The question is whether the organisations are.
Citations
-
Jeff Gothelf, SAFe Was Bad for Agility. For AI, It’s Catastrophic, April 2026. Insurance company case study: 8 months, 3 PI cycles, 21-slide deck, zero shipped features. “SAFe working exactly as designed.” ↩ ↩2 ↩3
-
AltexSoft, Scaled Agile Framework: Overview, Pros and Cons, Alternative. SAFe at 30% and growing. Criticism: prescriptive nature dilutes agile principles, closer to waterfall than agile, complexity overwhelming for teams. ↩
-
DZone, The AI4Agile Practitioners Report 2026. 83% of Agile practitioners use AI, but most spend ≤10% of their time with it. Integration uncertainty is the top barrier at 54.3%. ↩
-
Marty Cagan / SVPG, A Vision For Product Teams and AI Product Management 2 Years In. Feasibility risk lowered by AI agents; the bottleneck is now direction and learning, not implementation. Product teams must maximise problems-solved, not features-delivered. ↩ ↩2
-
JetBrains Research, “Which AI Coding Tools Do Developers Actually Use at Work?” April 2026. Survey of 10,000+ developers. Claude Code 18% work adoption, Codex CLI 3%, Google Antigravity 6%. ↩
-
Faros AI, Enterprise AI Coding Assistant Adoption: Scaling to Thousands. Launch-Learn-Run framework (18+ weeks). EdTech case study: 1,100% adoption growth, $10.6M productivity value vs $68K cost (15,324% ROI). 21% more tasks, 98% more PRs, 91% more review time. Apiiro: 10× more security findings. Human-in-the-loop architecture for enterprise. ↩ ↩2 ↩3 ↩4 ↩5 ↩6
-
Java Code Geeks, The AI Coding Assistant Has Been on Your Team for a Year. What Did It Actually Change?, April 2026. DORA: 25% AI adoption increase → 7.2% delivery stability decrease (“Vacuum Hypothesis”). 48% AI code contains security vulnerabilities. Code duplication 8.3%→12.3%. Refactoring collapsed 25%→<10%. Fortune 50: 1,000→10,000 monthly security findings. 11-week ramp-up for full productivity. Tools are “pair-programmers, not autopilots.” ↩ ↩2 ↩3 ↩4 ↩5 ↩6
-
Writer, Enterprise AI Adoption in 2026: Why 79% Face Challenges Despite High Investment. 79% of organisations face AI adoption challenges; 54% of C-suite say AI is “tearing their company apart.” Only 3% of developers report “high trust” in AI output. ↩ ↩2
-
Gartner, Predicts 2026: AI Agents Will Reshape Infrastructure & Operations. Over 40% of agentic AI projects will be cancelled by end of 2027. Only 11% deployed agentic AI by mid-2025 despite 99% planning to. ↩
-
Agility at Scale, SAFe Built-in Quality When AI Agents Write the Code. AI agents produce 98% more code volume with 1.7× more defects. 2.74× more XSS vulnerabilities. 8× more performance problems. 91% more review time required. Proposes 6-layer harness engineering governance. Harness Architect as staff-level role. ↩ ↩2 ↩3 ↩4
-
Addy Osmani, The 80% Problem in Agentic Coding. Comprehension debt: developers merge code they cannot explain days later. 48% don’t review AI code before committing. 38% find AI code harder to review than human code. 98% more PRs, 91% more review time. Spend 70% on problem definition, 30% on execution. “The future belongs to those who maintain coherent mental models.” ↩ ↩2 ↩3 ↩4 ↩5 ↩6
-
Agility at Scale, AI Maturity for SAFe Enterprises: The Missing Integration Framework. Four-dimension model, five maturity levels (AI-Aware → AI-Native). Aggregate maturity = minimum score. L2→L3 transition is the hardest. ↩ ↩2
-
Jeff Gothelf, Agile in the Age of AI, December 2025. Agile survives the AI era but must return to original principles of rapid iteration, not ceremonial overhead. ↩
-
Addy Osmani, How to Write a Good Spec for AI Agents, O’Reilly Radar, February 2026. GitHub analysis of 2,500+ agent configs: teams covering all 6 specification areas see dramatically fewer post-deployment bugs. Teams covering <4 areas see quality drop below human baseline. ↩ ↩2