Does Pi Outperform Codex CLI for Local Models? A Harness Comparison on the NVIDIA GB10
Does Pi Outperform Codex CLI for Local Models? A Harness Comparison on the NVIDIA GB10
The system prompt tax is the cost you pay before your coding agent writes a single line of code. Every token of instruction, tool schema, and safety guardrail consumes context that a local model — already constrained by memory and decode speed — cannot spend on your actual task.
Pi, Mario Zechner’s open-source coding agent, makes a radical bet: ship fewer than 1,000 tokens of system prompt and four tools. Codex CLI ships approximately 8,500 tokens of baseline prompt plus rich tool schemas. The question is straightforward: on a local model running on consumer hardware, does the lighter harness produce faster, better results?
This article reports the results of running four local models across three harness configurations on an NVIDIA GB10, all on a single benchmark task.
Setup
Hardware
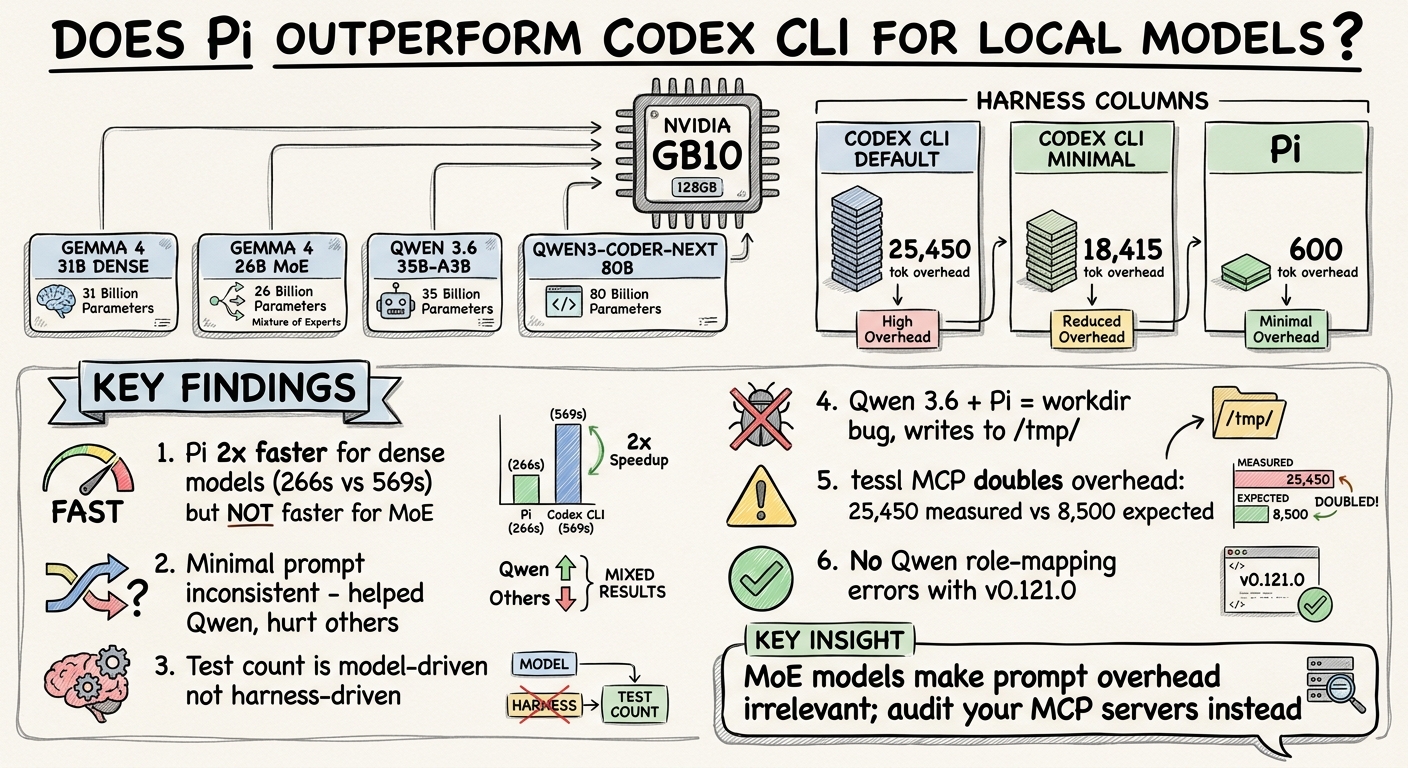
- NVIDIA GB10 — 128 GB unified memory, Blackwell GPU, running Ollama v0.20.5
- MacBook (client) — connected to GB10 via SSH tunnel (
localhost:11434) - Models run on the GB10; harnesses run on the Mac
Models
| Model | Architecture | Quantisation | Active Params |
|---|---|---|---|
| Gemma 4 31B Dense | Dense | Q4_K_M (~19 GB) | 31B |
| Gemma 4 26B MoE | Mixture of Experts | Q4_K_M (~17 GB) | 4B |
| Qwen 3.6 35B-A3B | Mixture of Experts | Q4_K_M (~23 GB) | 3B |
| Qwen3-Coder-Next 80B | Mixture of Experts | Q4_K_M (~51 GB) | 3B |
One dense model and three MoE models. This mix turned out to be the most revealing variable in the results.
Harnesses
| Harness | System Prompt Overhead | Description |
|---|---|---|
| Codex CLI (default) | ~25,450 tokens (measured) | Full system prompt, tool schemas, plan system, per-model instructions |
| Codex CLI (minimal) | ~18,415 tokens (measured) | Custom model_instructions_file replacing the built-in prompt (~105 tokens of instruction), include_permissions_instructions and include_apps_instructions disabled |
| Pi | ~600 tokens (estimated) | Minimal system prompt, 4 tools (read, write, edit, bash) |
All three harnesses ran through Ollama’s OpenAI-compatible API over the same SSH tunnel. Codex CLI version: v0.121.0. Pi version: v0.67.68.
The Task
The parse_csv_summary benchmark, used for comparability with previous tests:
Create a Python function called
parse_csv_summarythat takes a CSV file path, reads it, and returns a dictionary with: number of rows, number of columns, column names, and the data types of each column. Include error handling for missing files and malformed CSV. Then write tests for it.
Each run started from a clean git init directory. Tests were validated with pytest after each run.
Results
LOCAL MODEL BENCHMARK — 2026-04-19
Hardware: NVIDIA GB10 (128 GB unified, Blackwell)
Codex CLI: v0.121.0 | Pi: v0.67.68 | Ollama: v0.20.5
Codex (default) Codex (minimal) Pi
Model Time Tests Time Tests Time Tests
──────────────────────────────────────────────────────────────────────────────────
Gemma 4 31B Dense 569s 6/6 ✅ 584s 6/6 ✅ 266s 6/6 ✅
Gemma 4 26B MoE 83s 4/4 ✅ 127s 5/5 ✅ 79s 6/6 ✅
Qwen 3.6 35B-A3B 208s 16/16 ✅ 158s 11/11 ✅ ❌ (workdir bug)
Qwen3-Coder-Next 170s 13/13 ✅ 261s 15/15 ✅ 172s 19/19 ✅
Finding 1: Pi Is 2× Faster for Large Dense Models — but Not for MoE
The headline result: Pi completed the Gemma 4 31B Dense benchmark in 266 seconds versus Codex CLI’s 569 seconds — a 2.1× speedup. Both produced passing code with identical test counts.
But look at the MoE models. Gemma 4 26B: Pi 79s vs Codex 83s — negligible. Qwen3-Coder-Next: Pi 172s vs Codex 170s — effectively identical.
The likely explanation is prefill cost. Dense models process every token in the context through all parameters. A 25,000-token system prompt costs 31 billion parameters’ worth of compute on every prefill. MoE models route tokens through a fraction of their parameters (3–4B active out of 26–80B total), so the prefill cost of extra context tokens is dramatically lower.
This means Pi’s lightweight prompt advantage is architecture-dependent. If you are running a dense local model, the harness overhead matters. If you are running an MoE model — which is increasingly the default for local deployment — the system prompt size is noise.
Finding 2: The Minimal Prompt Is Inconsistent
The Codex CLI minimal configuration replaced the ~8,500-token default system prompt with a 105-token instruction file focused on git safety rules and basic guidelines. The hypothesis: fewer prompt tokens means faster inference and more available context.
The results were mixed:
| Model | Default | Minimal | Verdict |
|---|---|---|---|
| Gemma 4 31B Dense | 569s | 584s | Minimal slower (+15s) |
| Gemma 4 26B MoE | 83s | 127s | Minimal slower (+44s) |
| Qwen 3.6 35B-A3B | 208s | 158s | Minimal faster (−50s) |
| Qwen3-Coder-Next 80B | 170s | 261s | Minimal slower (+91s) |
Only Qwen 3.6 benefited. The others were slower — sometimes significantly.
Why? Fewer input tokens does not guarantee fewer total tokens. The minimal prompt produced more tool-call turns in some runs, and models without the default prompt’s structured instructions sometimes generated more verbose output. Qwen 3.6’s improvement may reflect its MoE architecture benefiting from the reduced prefill combined with its strong RL-trained coding behaviour compensating for the missing instructions.
The lesson: stripping system prompt tokens is not a reliable optimisation. The prompt’s content shapes the model’s execution plan, and a worse plan can cost more tokens than a longer prompt saves.
Finding 3: Test Count Is Model-Driven, Not Harness-Driven
A common assumption is that a richer system prompt produces more comprehensive code. The data does not support this:
| Model | Codex Default | Codex Minimal | Pi |
|---|---|---|---|
| Gemma 4 31B Dense | 6 tests | 6 tests | 6 tests |
| Gemma 4 26B MoE | 4 tests | 5 tests | 6 tests |
| Qwen 3.6 35B-A3B | 16 tests | 11 tests | ❌ |
| Qwen3-Coder-Next 80B | 13 tests | 15 tests | 19 tests |
Qwen 3.6 wrote 16 tests under Codex default. Qwen3-Coder-Next wrote 19 under Pi. The Gemma models consistently wrote 4–6 tests regardless of harness. The variation tracks with each model’s coding training data, not with the harness’s instructions.
This aligns with Pi’s thesis: frontier-class models (and even strong open-weight models) have been RL-trained extensively on coding agent behaviour. The harness does not need to teach them how to write tests — they already know.
Finding 4: Qwen 3.6 Has a Pi Working-Directory Bug
Qwen 3.6 under Pi consistently wrote output files to /tmp/ rather than the working directory. Reproduced across two independent runs. All other models used relative paths correctly under Pi.
Root cause: Pi does not inject the current working directory into its system prompt. Most models infer cwd from context (the bash tool’s output, git init in the task setup). Qwen 3.6 appears to have a strong /tmp/ prior from its training data that overrides this inference.
This is a harness-model interaction bug — neither Pi nor Qwen 3.6 is broken independently, but together they produce incorrect behaviour. Codex CLI’s default prompt includes explicit working-directory context, which prevents this class of error.
# Attempted workaround: explicit cwd in prompt
pi --model "ollama/qwen3.6:35b-a3b" -e ./pi-ollama.ts \
"You are in $(pwd). Create a Python function called 'parse_csv_summary'..."
# Not yet tested — potential fix for future runs
Finding 5: tessl MCP Doubles Codex’s Context Overhead
The most unexpected finding. Prior measurements (Alex Fazio, Codex v0.114.0) established Codex CLI’s baseline system prompt at approximately 8,500 tokens. Our measured overhead was 25,450 tokens — nearly 3× higher.
The cause: tessl MCP tool schemas were injected globally into all Codex CLI profiles. These schemas added approximately 7,000–10,000 tokens of tool definitions that appear in every conversation, regardless of whether tessl is used.
Codex (default) Codex (minimal) Pi
Measured overhead: ~25,450 tok ~18,415 tok ~600 tok (est.)
Expected (no MCP): ~8,500 tok ~1,500 tok ~600 tok
MCP inflation: ~17,000 tok ~17,000 tok N/A
The minimal prompt saved approximately 7,000 tokens by stripping the system prompt and permissions/apps sections. But the MCP schemas — identical in both profiles — dominated the total overhead.
On a 128K context window, 25,450 tokens of overhead consumes 20% of available context before the first user message. With MCP disabled, that drops to 7%. For local models where every token of context costs decode latency, this matters.
Action item: Disable unused MCP servers per-profile or globally when running local models. The config.toml profile system does not currently scope MCP servers — they apply globally.
Finding 6: No Qwen Role-Mapping Errors
A known issue with earlier Codex CLI versions: Qwen models would fail on the developer and toolResult roles used in Codex’s conversation format. Ollama’s OpenAI-compatible API needed to map these correctly.
With Codex CLI v0.121.0 and Ollama v0.20.5, all four models — including both Qwen variants — worked without role-mapping errors. No --oss fallback was needed. This combination appears stable for Qwen models.
How Our Results Compare to Published Benchmarks
A single-task benchmark on one machine tells you how these models performed here. Published benchmarks tell you how they perform generally. Comparing the two reveals whether our results are representative or anomalous.
The Models on Paper
| Model | SWE-bench Verified | LiveCodeBench v6 | Terminal-Bench 2.0 | Active Params | Architecture |
|---|---|---|---|---|---|
| Qwen 3.6 35B-A3B | 73.4 | 80.4 | 51.5 | 3B | MoE |
| Qwen3-Coder-Next 80B | 70.6 | — | 36.2 | 3B | Hybrid MoE (512 experts) |
| Gemma 4 31B Dense | ~52.0 | 80.0 | 42.9 | 31B | Dense |
| Gemma 4 26B MoE | — | 77.1 | — | 3.8B | MoE |
Sources: Qwen3.6 model card, Qwen3-Coder-Next HuggingFace, Gemma 4 benchmarks.
The ranking is striking. Qwen 3.6 — released just three days before this benchmark on April 16, 2026 — leads every coding benchmark. It scores 73.4 on SWE-bench Verified, competitive with frontier API models and 21 points above Gemma 4 31B Dense. Qwen3-Coder-Next, which Latent.Space describes as the “overwhelming consensus” pick for local coding agents, scores 70.6 — strong but slightly behind the newer, smaller Qwen 3.6.
Both Gemma 4 variants trail on SWE-bench. The 31B Dense scores approximately 52.0 — respectable but in a different league from the Qwen models. The 26B MoE has no published SWE-bench score but likely sits lower. Where Gemma 4 shines is in agentic tool use: the 31B Dense scores 86.4% on tau2-bench, a massive jump from Gemma 3’s broken 6.6%.
What the Benchmarks Predicted vs What We Measured
Qwen3-Coder-Next’s test thoroughness was expected. It wrote the most tests in our benchmark (19 under Pi, 15 under Codex minimal, 13 under Codex default). Community reports from XDA-Developers confirm this pattern: in a head-to-head test against four other local models, Qwen3-Coder-Next produced “clean project architecture, proper polling-based file watcher, and 14 passing tests” — described as “not even close” to the competition. Our results are consistent.
Qwen 3.6’s test volume was also predicted by its benchmarks. It wrote 16 tests under Codex default — second only to Qwen3-Coder-Next. Its SWE-bench Verified score of 73.4 suggests it should produce high-quality, comprehensive code, and it did. The working-directory bug under Pi (Finding 4) is a harness-model interaction issue, not a code quality issue.
Gemma 4’s lower test counts match its benchmark position. Both Gemma variants wrote 4–6 tests regardless of harness. This is consistent with a model that scores ~52 on SWE-bench producing functional but less comprehensive solutions. Community reports confirm Gemma 4 is “more consistent where it counts — actually compiling and running” but is not as thorough as the Qwen models in test generation.
The speed difference on dense vs MoE was predictable. Gemma 4 31B Dense processes every token through all 31B parameters. The MoE models activate only 3–4B parameters per token. Published inference benchmarks show Gemma 4 26B MoE achieving approximately 150 tokens/second on consumer hardware versus significantly lower speeds for the 31B Dense. Pi’s 2× speedup on the dense model (Finding 1) is a direct consequence: fewer prompt tokens × more parameters per token = larger absolute time savings.
What the Benchmarks Did Not Predict
Qwen3-Coder-Next and Qwen 3.6 were near-identical in speed on our task. Despite Qwen3-Coder-Next being a much larger model (80B total parameters vs 35B), both activate approximately 3B parameters per token. Our timings — 170s vs 208s under Codex default — reflect this architectural similarity. The benchmark scores suggest Qwen 3.6 should be slightly better at coding (73.4 vs 70.6 on SWE-bench), and it did write more tests in our single run, but the speed difference was negligible.
The minimal prompt’s inconsistency was not obvious from benchmarks. Published benchmarks test models with their default configurations, not with stripped-down harnesses. The finding that removing system prompt instructions can slow models (Finding 2) has no analogue in standard benchmark suites. This is a real-world harness interaction that benchmarks do not capture.
Gemma 4 26B MoE’s resilience to quantisation is well-documented — community testing shows identical results across Q4_K_M, MXFP4, and Q5_K_M quant levels. Our test used Q4_K_M for all models, so quantisation effects should be minimal, but this is worth noting: the Gemma 4 MoE is particularly robust at lower precision, which matters for the GB10’s memory-constrained environment.
Community Consensus: Which Model for Local Coding?
The r/LocalLLaMA and Latent.Space consensus as of April 2026:
- For agentic coding (IDE integration, tool-calling): Qwen3-Coder-Next remains the default recommendation due to months of community testing and proven IDE integration with Claude Code, Cline, and Codex CLI. Its SecCodeBench score of 61.2% — above Claude Opus 4.5’s 52.5% — makes it a strong choice for security-conscious code generation.
- For raw coding benchmarks: Qwen 3.6 35B-A3B leads on every published metric but was released only three days before our benchmark. Less community validation exists.
- For daily-driver use (speed + quality): Gemma 4 26B MoE is described by Latent.Space as “the better default for most English-first users doing coding and document work” due to its speed (~150 t/s), quantisation resilience, and ability to fit in ~8GB VRAM.
- For maximum reasoning quality: Gemma 4 31B Dense, when you have the VRAM budget for it.
Our benchmark adds one data point to this picture: the harness matters less than the model, MoE models neutralise prompt overhead, and MCP schema bloat is the optimisation most people are overlooking.
Conclusions
Pi’s speed advantage is real but architecture-specific. On the one dense model tested (Gemma 4 31B), Pi’s 2× speedup is significant and directly attributable to lower prefill cost from its minimal prompt. On MoE models, the advantage vanishes because prefill cost scales with active parameters, not total parameters.
System prompt stripping is not a reliable optimisation. The minimal Codex configuration was slower in 3 of 4 cases. The prompt shapes the model’s execution plan; a shorter prompt can produce a longer, slower execution.
MCP schema overhead is the bigger lever. Disabling unused MCP servers would save approximately 17,000 tokens — more than the entire difference between Codex’s default and minimal prompts. For local model users, auditing MCP configuration is the highest-impact optimisation.
Test quality is model-dependent. The harness does not meaningfully influence how many tests a model writes or how comprehensive they are. Choose your model for code quality; choose your harness for speed and integration.
Next Steps
- Re-run the benchmark with tessl MCP disabled globally to isolate the true prompt overhead comparison (~8,500 vs ~1,500 vs ~600 tokens)
- Test the Qwen 3.6 + Pi working-directory bug with explicit cwd injection in the prompt
- Expand to a multi-task benchmark —
parse_csv_summaryis a single data point; a suite of 5–10 tasks would strengthen the findings - Test with llama.cpp server as an alternative backend — different quantisation handling may shift the dense-model results
Benchmark run: 19 April 2026, Starbucks Cambridge → Clayton Hotel lobby. Hardware: NVIDIA GB10 (128 GB unified). All raw logs and configuration files available in projects/gemma4-qwen36/.
Sources
- Qwen3-Coder-Next model card (HuggingFace) — SWE-bench Verified 70.6, SWE-bench Pro 44.3, SecCodeBench 61.2%
- Qwen3.6-35B-A3B announcement (Alibaba Cloud) — SWE-bench Verified 73.4, Terminal-Bench 2.0 51.5, LiveCodeBench v6 80.4
- Gemma 4 coding performance benchmarks — LiveCodeBench v6 80.0, tau2-bench 86.4%
- XDA: Qwen3-Coder-Next vs 4 local models — “one of the best local models out there, and it’s not even that close”
- Latent.Space: Top local models, April 2026 — Qwen3-Coder-Next described as “the overwhelming consensus”
- The Decoder: Qwen3.6 vs Gemma 4 — head-to-head benchmark comparison
- Quantised Go coding benchmark: Gemma 4 vs Qwen — real-world compilation and runtime testing