ProdCodeBench and Production-Derived Evaluation: Why Synthetic Benchmarks Mislead and How to Evaluate Codex CLI Against Real Workloads
ProdCodeBench and Production-Derived Evaluation: Why Synthetic Benchmarks Mislead and How to Evaluate Codex CLI Against Real Workloads
The Benchmark Problem
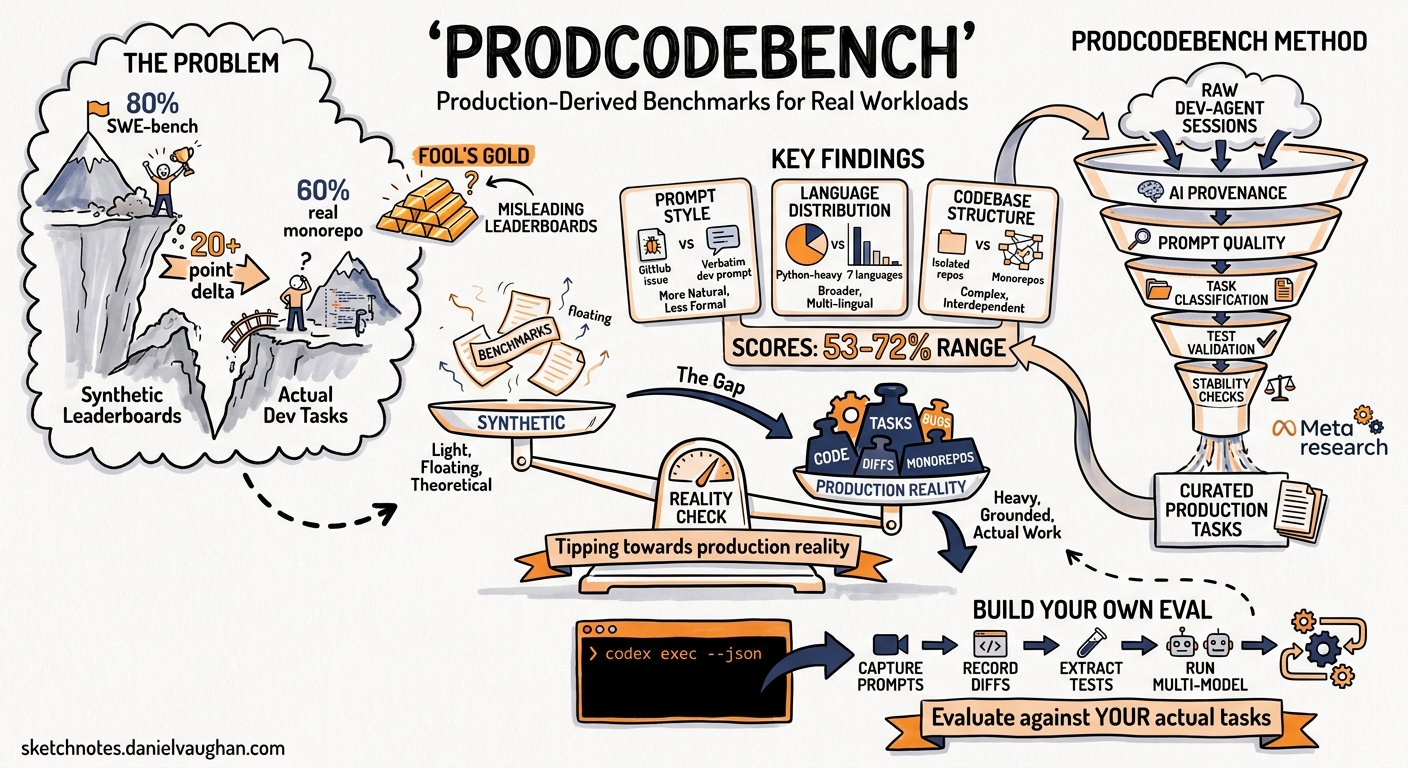
Most teams selecting a coding agent rely on public leaderboards — SWE-bench Verified, Terminal-Bench 2.0, Aider Polyglot — to inform their choice. These benchmarks serve a purpose, but Meta’s ProdCodeBench research (April 2026) exposes a structural gap: synthetic benchmarks diverge from production workloads in prompt style, language distribution, and codebase structure1. The solve-rate delta between public benchmarks and internal evaluations can exceed 20 percentage points2, meaning a model that scores 80% on SWE-bench Verified may achieve barely 60% on your actual monorepo tasks.
This article examines ProdCodeBench’s methodology, extracts the principles that matter for Codex CLI practitioners, and provides a practical pipeline for building production-derived evaluations using codex exec --json.
What ProdCodeBench Reveals
Methodology
ProdCodeBench, developed by researchers at Meta1, curates benchmark tasks from real developer-agent conversations rather than GitHub issues written for human communication. Each sample consists of three components:
- Verbatim prompt — the exact text a developer typed to the coding agent
- Committed code change — the production diff that was merged
- Fail-to-pass tests — tests spanning seven programming languages that validate correctness
The curation pipeline applies multiple filtering stages1:
flowchart TD
A[Raw developer-agent sessions] --> B[AI provenance filtering]
B --> C[Prompt quality filters]
C --> D[LLM-based task classification]
D --> E[Test relevance validation]
E --> F[Multi-run stability checks]
F --> G[ProdCodeBench tasks]
C -->|Excluded| H[Solution leakage]
C -->|Excluded| I[Non-testable prompts]
C -->|Excluded| J[Template messages]
F -->|Excluded| K[Flaky tests]
Key Findings
Across four foundation models, solve rates ranged from 53.2% to 72.2%1 — significantly below the 80%+ scores these same model families achieve on SWE-bench Verified3. The gap stems from three structural differences:
| Dimension | SWE-bench | ProdCodeBench |
|---|---|---|
| Prompt origin | GitHub issue descriptions | Verbatim developer prompts |
| Context assumptions | Self-contained | Enterprise context, implicit knowledge |
| Codebase structure | Individual OSS repos | Monorepo with cross-service dependencies |
| Language coverage | Predominantly Python | Seven languages reflecting production mix |
The Monorepo Problem
ProdCodeBench identifies a “time travel problem” unique to production evaluation1: distributed services continuously index the latest state, developer tooling expires within 30–365 days, build indices expire within days, and CI metadata retention is limited. This motivates a rolling benchmark design with periodic task refreshes rather than a fixed dataset — a pattern directly applicable to Codex CLI evaluation in enterprise environments.
Why This Matters for Codex CLI Teams
Public Benchmarks as Directional Signal Only
Current public scores for Codex CLI’s underlying models34:
- SWE-bench Verified: GPT-5.2 achieves 80.0%; GPT-5.4-Codex leads SWE-bench Pro at 56.8%
- Terminal-Bench 2.0: GPT-5.3 Codex scores ~77.3%, GPT-5.5 reaches 82.0%
- Aider Polyglot: GPT-5.3 scores ~80%
These numbers tell you which models are broadly capable. They do not tell you whether Codex CLI will correctly refactor your payment service’s retry logic, navigate your monorepo’s build system, or follow your team’s commit conventions. ProdCodeBench demonstrates that the same models score 10–25 points lower on production-derived tasks12.
The Three Gaps
Production workloads introduce challenges that synthetic benchmarks rarely exercise:
- Implicit context — production prompts assume knowledge of internal APIs, naming conventions, and architectural decisions
- Cross-service dependencies — changes that span multiple packages with shared types and configuration
- Non-functional requirements — logging standards, error handling patterns, test coverage thresholds enforced by CI
Building Production-Derived Evals for Codex CLI
Step 1: Capture Real Sessions
Codex CLI’s rollout files provide the raw material. Every interactive session produces a session rollout stored in ~/.codex/sessions/5. For codex exec invocations, use --json to capture structured JSONL events:
codex exec --json \
--model gpt-5.3-codex \
"Refactor the retry logic in payments/client.go to use exponential backoff" \
2>/dev/null | tee /tmp/eval-session.jsonl
The JSONL stream includes every tool call, file edit, and command execution as structured events6.
Step 2: Classify and Filter Tasks
Not every session makes a good benchmark task. Apply ProdCodeBench’s classification criteria:
# Extract sessions where tests went from failing to passing
codex exec --json --output-schema '{"type":"object","properties":{"testable":{"type":"boolean"},"task_type":{"type":"string"},"complexity":{"type":"string"}}}' \
"Analyse this session trace and classify: is the task testable (has fail-to-pass tests), what type (bug_fix|feature|refactor), and complexity (low|medium|high)?" \
< /tmp/eval-session.jsonl
Step 3: Build the Eval Harness
OpenAI’s recommended pattern uses codex exec --json with layered grading6:
flowchart LR
A[Prompt + Repo State] --> B[codex exec --json]
B --> C[JSONL Trace]
C --> D[Deterministic Graders]
C --> E[Rubric-based Graders]
D --> F[Score]
E --> F
D -->|Checks| G[Tests pass?]
D -->|Checks| H[Correct files modified?]
D -->|Checks| I[No forbidden commands?]
E -->|Checks| J[Code style compliance]
E -->|Checks| K[Convention adherence]
A minimal eval script:
#!/usr/bin/env bash
set -euo pipefail
EVAL_DIR="$1"
PROMPT=$(cat "$EVAL_DIR/prompt.txt")
REPO_STATE=$(cat "$EVAL_DIR/repo_sha.txt")
# Reset to known state
git checkout "$REPO_STATE" --quiet
# Run the agent
codex exec --json \
--model gpt-5.3-codex \
--approval-mode full-auto \
"$PROMPT" > "$EVAL_DIR/trace.jsonl" 2>"$EVAL_DIR/stderr.log"
# Deterministic grading
TEST_RESULT=$(cd "$EVAL_DIR/repo" && make test 2>&1 && echo "PASS" || echo "FAIL")
MODIFIED_FILES=$(git diff --name-only)
# Score
jq -n \
--arg test_result "$TEST_RESULT" \
--arg modified "$MODIFIED_FILES" \
'{test_pass: ($test_result == "PASS"), files_modified: ($modified | split("\n") | length)}' \
> "$EVAL_DIR/score.json"
Step 4: Multi-Run Stability
ProdCodeBench’s key insight: each model must be evaluated multiple times to quantify variance1. Non-deterministic outcomes without code changes indicate flaky tests that should be excluded. For Codex CLI evaluations:
# eval-config.toml
[eval]
runs_per_task = 3
stability_threshold = 0.67 # 2/3 runs must agree
model = "gpt-5.3-codex"
reasoning_effort = "medium"
[eval.exclude_patterns]
flaky_tests = ["**/integration/network_*", "**/e2e/timing_*"]
Step 5: Rolling Refresh
Following ProdCodeBench’s rolling benchmark design, refresh your eval set periodically:
# Weekly: extract new sessions from the past 7 days
find ~/.codex/sessions -mtime -7 -name "*.jsonl" \
| xargs -I{} codex exec --json \
"Classify this session for eval suitability" < {} \
>> /tmp/new-candidates.jsonl
Production Eval Patterns for Codex CLI
Pattern 1: Regression Detection
Compare solve rates across model upgrades:
for model in "gpt-5.3-codex" "gpt-5.4-codex" "gpt-5.5"; do
codex exec --json --model "$model" \
--approval-mode full-auto \
"$(cat eval/task-042/prompt.txt)" \
> "eval/task-042/trace-${model}.jsonl"
done
Pattern 2: Configuration A/B Testing
Test whether reasoning effort or approval mode affects production task completion:
# profiles for eval comparison
[profile.eval-medium]
model = "gpt-5.3-codex"
reasoning_effort = "medium"
[profile.eval-high]
model = "gpt-5.3-codex"
reasoning_effort = "high"
Pattern 3: Harness-Aware Scoring
Use Promptfoo’s Codex SDK provider7 for structured evaluation with trajectory assertions, token tracking, and skill usage verification — aligning with ProdCodeBench’s emphasis on process goals alongside outcome goals.
Decision Framework
flowchart TD
Q1{Choosing between models?} -->|Yes| A[Use public benchmarks as shortlist]
Q1 -->|No| Q2{Validating for your codebase?}
Q2 -->|Yes| B[Build production-derived eval set]
Q2 -->|No| Q3{Tracking regression across updates?}
Q3 -->|Yes| C[Rolling eval with stability checks]
Q3 -->|No| D[Manual spot-checking sufficient]
A --> E[Then validate with production evals]
B --> F[Minimum 50 tasks, 3 runs each]
C --> G[Weekly refresh, monthly full sweep]
Current Limitations
- ⚠️ ProdCodeBench’s full dataset is not publicly available — the paper describes methodology rather than releasing a reusable benchmark
- ⚠️ The “time travel problem” means production evals have a shelf life; tasks become stale as codebases evolve
- ⚠️
codex exec --jsonreasoning-token reporting (added in v0.125.08) helps with cost tracking but does not yet integrate with eval frameworks natively - ⚠️ Multi-run stability checks triple evaluation cost — budget accordingly when using paid models
Recommendations
- Treat public benchmarks as a filter, not a decision — use SWE-bench Verified and Terminal-Bench 2.0 to shortlist models, then validate against your own workload
- Start small — 20–30 production-derived tasks with fail-to-pass tests provide more signal than thousands of synthetic problems
- Capture verbatim prompts — ProdCodeBench shows that real developer prompts behave differently from cleaned-up issue descriptions
- Implement rolling refresh — eval tasks older than 90 days should be reviewed for relevance given codebase evolution
- Score process, not just outcome — use JSONL traces to verify Codex CLI followed intended tool sequences and conventions
Citations
-
Jha, S., Paltenghi, M., Maddila, C., Murali, V., Ugare, S., & Chandra, S. (2026). “ProdCodeBench: A Production-Derived Benchmark for Evaluating AI Coding Agents.” arXiv:2604.01527. https://arxiv.org/abs/2604.01527 ↩ ↩2 ↩3 ↩4 ↩5 ↩6 ↩7
-
Meta AI Research internal evaluation results as reported in ProdCodeBench, showing 53.2%–72.2% solve rates vs. 80%+ on synthetic benchmarks. https://arxiv.org/html/2604.01527v1 ↩ ↩2
-
Morphllm. “AI Coding Benchmarks 2026: Every Major Eval Explained and Ranked.” https://www.morphllm.com/ai-coding-benchmarks-2026 ↩ ↩2
-
Terminal-Bench 2.0 Leaderboard. BenchLM.ai. https://benchlm.ai/benchmarks/terminalBench2 ↩
-
OpenAI. “Codex CLI Features — Session resumption.” https://developers.openai.com/codex/cli/features ↩
-
OpenAI. “Testing Agent Skills Systematically with Evals.” https://developers.openai.com/blog/eval-skills ↩ ↩2
-
Promptfoo. “OpenAI Codex SDK — Evaluate Coding Agents.” https://www.promptfoo.dev/docs/providers/openai-codex-sdk/ ↩
-
OpenAI. “Codex CLI Changelog — v0.125.0.” https://developers.openai.com/codex/changelog ↩