The AI Capability Gap: Why Karpathy Says Codex CLI Users Live in a Different Reality
The AI Capability Gap: Why Karpathy Says Codex CLI Users Live in a Different Reality
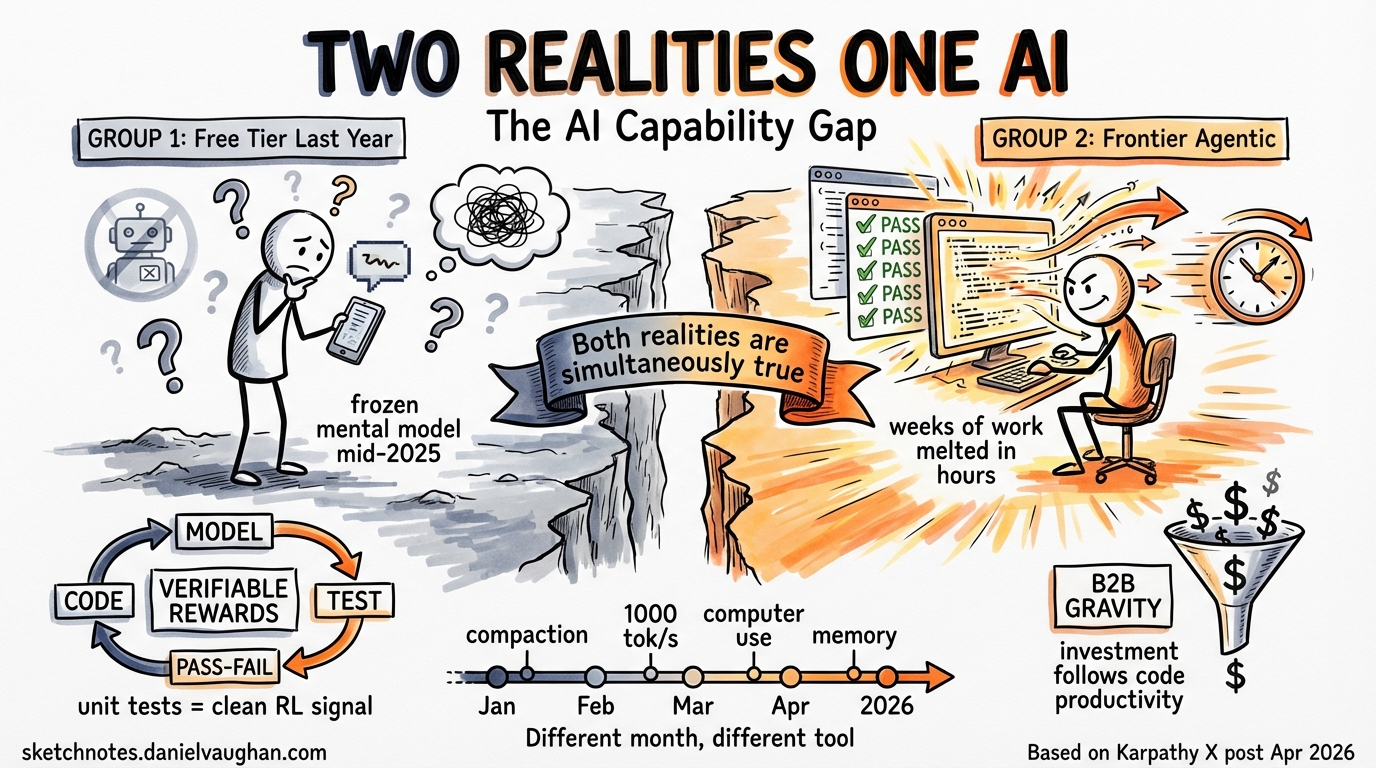
Andrej Karpathy posted a thread on April 9, 2026 that crystallised something Codex CLI practitioners have felt for months: the people who use frontier agentic models professionally and the people who tried free-tier ChatGPT last year are living in different realities 1. The gap is not a matter of opinion. It is a direct consequence of how reinforcement learning works, where commercial incentives point, and what “using AI” actually means in 2026.
This article unpacks Karpathy’s argument, maps it onto concrete Codex CLI workflows, and examines why the capability gap is structural rather than temporary.
The Two Groups
Karpathy identifies two populations talking past each other.
Group 1 tried a free or outdated model — often the free tier of ChatGPT or an older GPT-4 variant — and formed a view of AI capabilities from that experience. They see hallucinations, fumbled voice queries, and viral failure videos. Their mental model of “what AI can do” is frozen somewhere around mid-2025.
Group 2 pays for frontier models and uses them in technical domains: programming, mathematics, research. This group watches current-generation agents “melt programming problems that you’d normally expect to take days/weeks of work” 1. They assign far greater weight to the trajectory and its implications.
The disconnect is not about optimism versus realism. Both observations are simultaneously true. OpenAI’s free Advanced Voice Mode will fumble basic questions while, at the same time, the highest-tier Codex model will autonomously restructure an entire codebase over an hour-long session. The same company, the same month, radically different capability tiers.
Why the Gap Is Structural: Verifiable Rewards
Karpathy attributes the lopsided progress to two reinforcing factors, and they matter for understanding where Codex CLI sits.
Factor 1: Reinforcement learning needs verifiable reward signals. Code has them in abundance. A unit test passes or it does not. A type checker accepts or rejects. A build succeeds or fails. These binary outcomes provide the clean reward signals that RL training thrives on 2. Writing, advice, and search — the tasks most free-tier users evaluate — lack equivalent signals. Judging whether a paragraph of prose is “good” requires human preference data, which is noisy, expensive, and slow. Code verification is cheap, fast, and unambiguous.
This is why gpt-5.3-codex and gpt-5.4 are so much better at programming than their predecessors: they were trained with RL against verifiable coding benchmarks at a scale and fidelity that is simply not possible for open-ended conversational tasks 3.
Factor 2: B2B value concentrates investment. Enterprise customers pay for coding productivity gains. A model that saves an engineering team 20 hours per week justifies a $200/month subscription hundreds of times over. A model that writes slightly better birthday messages does not. The economic gravity pulls the best researchers, the most compute, and the tightest feedback loops toward the high-value technical domains.
For Codex CLI users, this means the tool improves faster than your intuition expects, because the investment flywheel is specifically aimed at the workflows you use it for.
What “Melting Problems” Looks Like in Practice
Karpathy’s phrase — “melt programming problems that you’d normally expect to take days/weeks of work” — sounds like hyperbole until you have seen it. Here is what it maps to in Codex CLI terms.
Multi-file refactoring. A task like “migrate this Express.js API from callbacks to async/await, update all 47 route handlers, fix the error handling, and ensure all tests pass” is a concrete example. A senior developer budgets two to three days. Codex CLI, running in codex exec --full-auto with sub-agent delegation, completes it in under an hour — reading each file, applying changes, running the test suite, fixing failures, and iterating until green 4.
Codebase-wide audits. “Find every SQL query in this monorepo that is vulnerable to injection, generate parameterised replacements, and write regression tests for each” is a task that would take a security team a week of focused work. A Codex CLI session with appropriate AGENTS.md context and sub-agent fan-out handles it in a single sitting 5.
Exploratory debugging. A production bug that manifests only under specific concurrency conditions. The agent reads logs, forms hypotheses, instruments code with targeted logging, runs load tests, narrows the root cause, and proposes a fix — all without human intervention beyond the initial prompt. The feedback loop between hypothesis and verification is exactly the kind of tight, verifiable cycle that RL-trained models excel at.
None of these examples require exotic configuration. They use standard Codex CLI features: sub-agent delegation for parallelism 4, workspace-write sandbox mode for safety 6, hooks for policy enforcement 7, and the /compact command for context management in long sessions 8.
The Recency Problem
Karpathy’s first point — that many people’s AI mental model is stale — deserves emphasis. The pace of improvement in agentic coding tools is not intuitive.
Consider the progression in Codex CLI alone over the past four months:
- January 2026:
gpt-5.3-codexintroduced native context compaction, making long sessions reliable for the first time 3. - February 2026:
gpt-5.3-codex-sparkon Cerebras hardware hit 1,000 tokens per second, enabling rapid multi-implementation comparison workflows 9. - March 2026:
gpt-5.4added computer use capabilities, scoring 75% on OSWorld — surpassing the human baseline of 72.4% — plus tool search with deferred loading that cut MCP schema token overhead by 47% 10. - April 2026: Memory extensions, prefix compaction, MCP elicitations, and cross-platform hooks landed in rapid succession 11.
Someone who tried Codex CLI in December 2025 and someone using it today are not using the same tool in any meaningful sense. The December user had a capable but limited assistant. The April user has an agent that maintains persistent memory across sessions, manages its own context window proactively, and coordinates parallel sub-agents on complex multi-file tasks.
The Perception Tax
The capability gap creates a practical problem beyond philosophical disagreement: it distorts institutional decision-making.
When a CTO evaluates whether to adopt agentic coding tools, the evaluation is often informed by the “Group 1” mental model — someone on the leadership team who had a mediocre experience with a consumer AI product. The result is a perception tax: teams that could benefit from frontier agentic tools face organisational resistance rooted in outdated capability assessments.
The antidote is demonstration, not argument. Karpathy’s thread will not convince a sceptic. A recorded session where Codex CLI autonomously completes a real task from the team’s backlog — start to finish, with the clock running — will. The verifiable reward signal that makes RL training work also makes capability demonstration unambiguous: the code compiles, the tests pass, the PR is mergeable.
The Uncomfortable Trajectory
Karpathy describes the second group as experiencing “AI Psychosis” — a term that captures the disorientation of watching capabilities improve faster than your ability to update your mental model. The gap between what you saw last month and what the tool can do this month keeps widening.
For Codex CLI practitioners, the implication is straightforward: the tool you are using today is the worst version you will ever use. Every workflow you design should assume the agent will be substantially more capable in three months. Build your AGENTS.md files, your hook policies, your sub-agent architectures, and your approval workflows with headroom for an agent that is smarter, faster, and more autonomous than the one you are configuring for today.
The two groups Karpathy describes are not going to converge through debate. They will converge when the capability becomes undeniable at every tier — when the free-tier experience catches up to what the frontier looks like today. Until then, the gap is real, it is structural, and if you are in Group 2, your job is to build the guardrails and workflows that let your organisation capture the value safely.
Key Takeaways
- Karpathy identifies a structural gap between people who tried free-tier AI last year and professionals using frontier agentic models today — both observations are simultaneously valid.
- The gap exists because reinforcement learning thrives on verifiable rewards (unit tests, type checks, build results), which code provides abundantly and open-ended conversation does not.
- B2B economics concentrate investment on the technical domains where agentic tools are deployed professionally, accelerating improvement in exactly those areas.
- Codex CLI capabilities have changed fundamentally in four months — anyone whose mental model predates January 2026 is evaluating a different tool.
- The antidote to the perception gap is demonstration: recorded sessions completing real tasks with verifiable outcomes, not arguments about potential.
-
Andrej Karpathy (@karpathy), X post, April 9, 2026. Quote-tweeting @staysaasy: “The degree to which you are awed by AI is perfectly correlated with how much you use AI to code.” https://x.com/karpathy/status/2042334451611693415 ↩ ↩2
-
Reinforcement Learning from Human Feedback (RLHF) and verifiable reward training. The key distinction is that code tasks provide automated verification (test suites, compilers, linters) while conversational tasks require expensive human preference judgments. ↩
-
Codex CLI Model Lineage: The Context Compaction Breakthrough. https://codex.danielvaughan.com/2026/03/28/codex-model-lineage-context-compaction/ ↩ ↩2
-
Codex CLI Subagents: TOML Format, Parallelism and spawn_agents_on_csv. https://codex.danielvaughan.com/2026/03/26/codex-cli-subagents-toml-parallelism/ ↩ ↩2
-
Codex CLI for CI/CD: codex exec, Non-Interactive Mode and Pipeline Integration. https://codex.danielvaughan.com/2026/03/26/codex-cli-cicd-non-interactive/ ↩
-
Codex CLI Approval Modes and Sandbox Security Model. https://codex.danielvaughan.com/2026/03/26/codex-cli-approval-modes-sandbox-security/ ↩
-
Codex CLI Hooks Deep Dive: SessionStart, Stop and userpromptsubmit. https://codex.danielvaughan.com/2026/03/26/codex-cli-hooks-deep-dive/ ↩
-
Context window management and the /compact command. See Chapter 15 of “Codex CLI: Agentic Engineering from First Principles.” ↩
-
GPT-5.3-Codex-Spark and the Cerebras Inference Stack: Real-Time Coding at 1,000 Tokens per Second. https://codex.danielvaughan.com/2026/03/31/codex-spark-cerebras-real-time-coding/ ↩
-
GPT-5.4 Computer Use and Tool Search in Codex CLI. https://codex.danielvaughan.com/2026/03/31/gpt54-computer-use-tool-search-codex-cli/ ↩
-
Codex CLI changelog, April 2026. Features merged into v0.118.x release train including memory extensions, prefix compaction, MCP elicitations, and cross-platform hooks. ↩