Karpathy's LLM Knowledge Bases: The Same Flywheel We've Been Running for Six Weeks
Karpathy’s LLM Knowledge Bases: The Same Flywheel We’ve Been Running for Six Weeks
On April 11, 2026, Andrej Karpathy posted a detailed description of his workflow for building personal knowledge bases with LLMs1. He described raw data ingestion, LLM-compiled wikis, Q&A against the accumulated knowledge, visual outputs filed back into the wiki, and automated linting passes to improve data integrity. The post resonated widely — 573 upvotes on r/Agent_AI within hours.
Reading it felt like looking at a blueprint of the system this site already runs on.
The codex-resources repository — the one that generates every article on this site, including this one — has been operating an almost identical architecture since early March 2026. Not because we read Karpathy’s post and copied it. Because the constraints of LLM-driven knowledge work push you toward the same design. That convergence is worth examining.
The Architecture, Side by Side
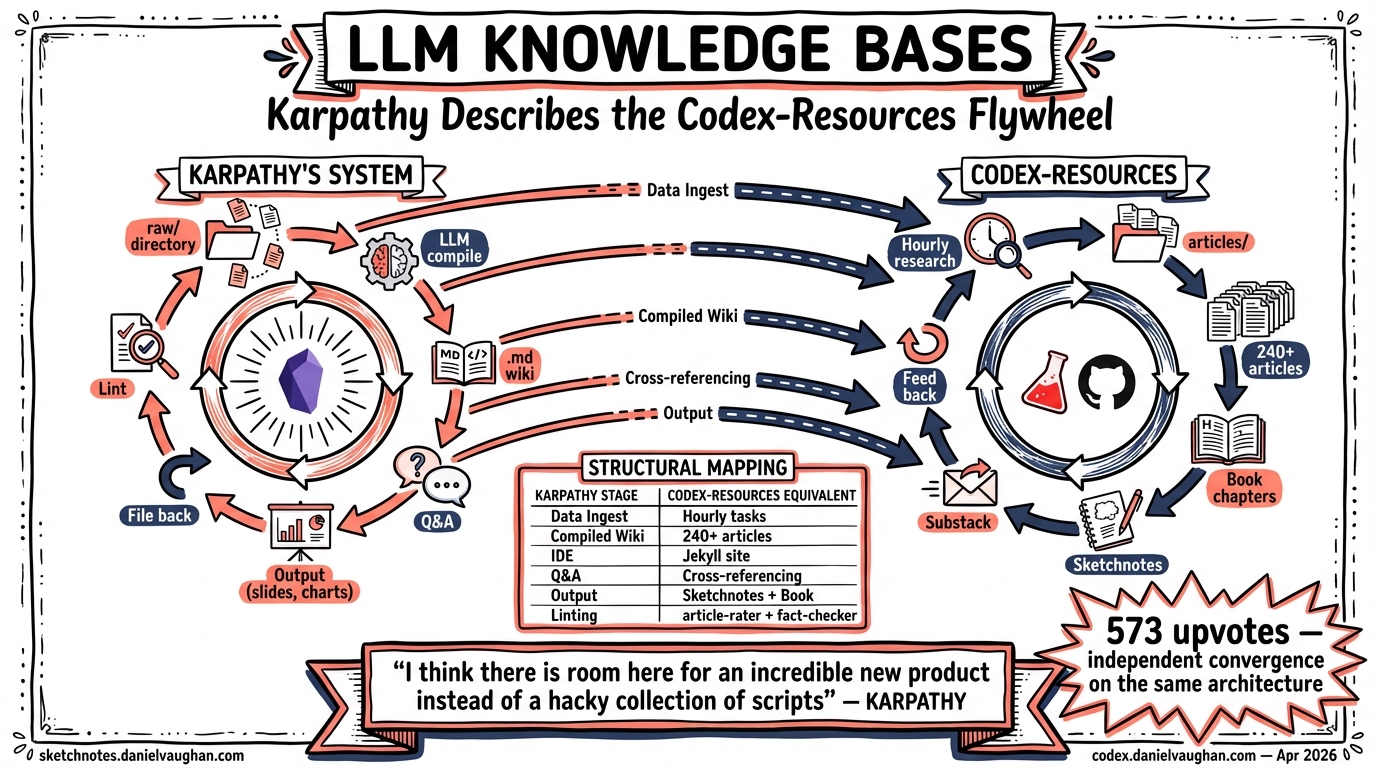
Karpathy describes six stages. Each one maps directly to a codex-resources component.
| Karpathy’s Stage | What He Does | What codex-resources Does |
|---|---|---|
| Data Ingest | Index source docs (articles, papers, repos, images) into raw/ directory |
Hourly research tasks scan GitHub PRs, changelogs, Reddit, HN, YouTube. The codex-kb skill ingests URLs, tips, and findings into articles/, notes/, and resources/ |
| Compiled Wiki | LLM compiles raw/ into a structured collection of .md files with summaries, backlinks, and categorised concepts |
240+ articles, each LLM-written from source material. Taxonomy files, cross-references, article index with metadata. Book chapters compiled from article corpus |
| IDE / Frontend | Obsidian as the viewing layer for raw data, wiki, and visualisations | Jekyll site at codex.danielvaughan.com — articles, sketchnotes, and book chapters rendered as a browsable knowledge base |
| Q&A | Ask complex questions against the wiki; LLM researches answers from the accumulated data | Every new article draws on the existing corpus. The LLM reads the knowledge base, cross-references, identifies gaps, writes new content that fits the existing structure |
| Output → Filed Back | Render markdown, slideshows, matplotlib images; file outputs back into the wiki to enhance it | Sketchnotes generated for every article. Book chapters synthesised from articles. Substack drafts converted from articles. Each output feeds back into the repo |
| Linting | Health checks: find inconsistencies, impute missing data, discover connections, suggest new article candidates | article-rater skill scores every article. citation-checker fixes formatting. fact-checker verifies claims. EDITORIAL-FINDINGS.md tracks structural issues. Article backlog identifies gaps |
The overlap is not approximate. It is structural.
Where Karpathy’s System and codex-resources Diverge
The differences are instructive.
Scale of automation. Karpathy describes manual triggers — he indexes sources, he asks questions, he runs health checks. The codex-resources system automates the ingest layer: scheduled tasks run hourly to scan for new Codex CLI developments, generate articles, create sketchnotes, and push commits. The LLM does not wait to be asked. It runs on a schedule and files its findings.
Output diversity. Karpathy mentions markdown, Marp slides, and matplotlib images. codex-resources produces articles, sketchnotes (generated via Gemini image models), book chapters (32 chapters, ~124,000 words), Substack-ready drafts, song lyrics, and a full Jekyll site. The principle is the same — multiple output formats from the same knowledge base — but the range is wider because the system has been running for weeks rather than being described conceptually.
The book as a forcing function. Karpathy’s wiki exists to serve Q&A. The codex-resources knowledge base serves a specific goal: a 32-chapter O’Reilly book proposal at ~410 pages. The book acts as a structural forcing function. Every article must eventually contribute to a chapter. Chapters with thin word counts (ch02 at 1,400 words, ch07 at 1,400 words) drive targeted research to fill gaps. The book’s table of contents is the ontology — it determines what topics need more coverage and which are adequately mapped.
Toolchain. Karpathy uses Obsidian, its web clipper, and local scripts. codex-resources uses Codex CLI / Claude Code as the LLM layer, Jekyll as the frontend, GitHub as the store, NanoClaw for scheduling, and custom skills (sketchnote-generator, fact-checker, article-rater, codex-yt-curator) as the tooling layer. The Obsidian-vs-Jekyll choice is aesthetic; the architecture underneath is the same.
Why Convergent Design Happens
Karpathy arrives at the same architecture independently because the constraints are universal:
-
LLMs work best on structured text. Markdown in directories is the lowest-friction format for both human reading and LLM manipulation. Not databases, not JSON, not proprietary formats. Plain
.mdfiles in a folder hierarchy. -
Context windows are large enough to skip RAG at small scale. Karpathy notes that at ~400K words, “the LLM has been pretty good about auto-maintaining index files and brief summaries” without needing vector search. The codex-resources corpus is now ~500K words across all articles and book chapters, and the same observation holds: index files and structured directories let the LLM navigate without embeddings.
-
Outputs must feed back into inputs. A knowledge base that only answers questions is a dead end. Karpathy’s “filing outputs back into the wiki to enhance it for further queries” is the flywheel. In codex-resources, every article potentially generates a sketchnote, a book chapter section, a Substack draft, and backlog entries for follow-up research. Each output enriches the corpus for the next query.
-
Linting is maintenance, not a feature. Both systems treat automated quality passes as essential infrastructure, not optional extras. Without them, the wiki accumulates inconsistencies faster than a human can spot them.
The Missing Product
Karpathy ends his post with: “I think there is room here for an incredible new product instead of a hacky collection of scripts.”
He is right. The codex-resources system is itself a hacky collection of scripts — skills, scheduled tasks, and CI pipelines stitched together with git commits. It works, but the operational overhead is real. The pieces that would make this a product:
- Declarative ingest pipelines. Define sources (GitHub repos, RSS feeds, subreddits, YouTube channels) and let the system poll, extract, and file without per-source scripting.
- Schema-aware compilation. The “compile raw into wiki” step currently requires detailed prompts about structure. A product would infer the ontology from the existing corpus and slot new content automatically.
- Multi-format output as a first-class feature. Today, generating a sketchnote or a book chapter requires invoking a specific skill. A product would expose output format as a parameter: “add this source and generate article + sketchnote + book chapter delta.”
- Conflict resolution. When two sources contradict each other, the system should flag the conflict rather than silently overwriting. The codex-resources linting layer catches some of this; a product would catch all of it.
What This Validates
Karpathy’s post validates two things about the codex-resources approach.
First, the architecture is not accidental. When one of the field’s most respected practitioners independently arrives at the same data-ingest → LLM-compiled-wiki → Q&A → output-filed-back → linting pipeline, the design is not a personal quirk. It is what LLM-driven knowledge work converges on.
Second, the value is in the accumulated corpus, not the tooling. Karpathy’s tools (Obsidian, scripts) and Daniel’s tools (Jekyll, NanoClaw, skills) are different. The 240+ articles, the cross-references, the book chapters synthesised from six weeks of daily research — that corpus is the asset. The tools are replaceable; the compiled knowledge is not.
Six weeks of running this system produced a 32-chapter book manuscript, 240+ articles, 200+ sketchnotes, and a live knowledge base that answers questions about Codex CLI faster than any search engine. Karpathy’s post describes the same machine. The only difference is that one of them has been running in production.
Citations
-
Andrej Karpathy, “LLM Knowledge Bases” — posted on X (April 11, 2026) and cross-posted to r/Agent_AI. Describes a personal workflow for building LLM-compiled knowledge bases using raw data ingestion, markdown wikis, Obsidian as IDE, Q&A against the corpus, visual output generation, and automated linting. 573 upvotes on Reddit within hours of posting. https://x.com/karpathy/status/2039805659525644595 ↩