Custom CUDA Kernels with Codex CLI: The Hugging Face Agent Skill for GPU Programming
Custom CUDA Kernels with Codex CLI: The Hugging Face Agent Skill for GPU Programming
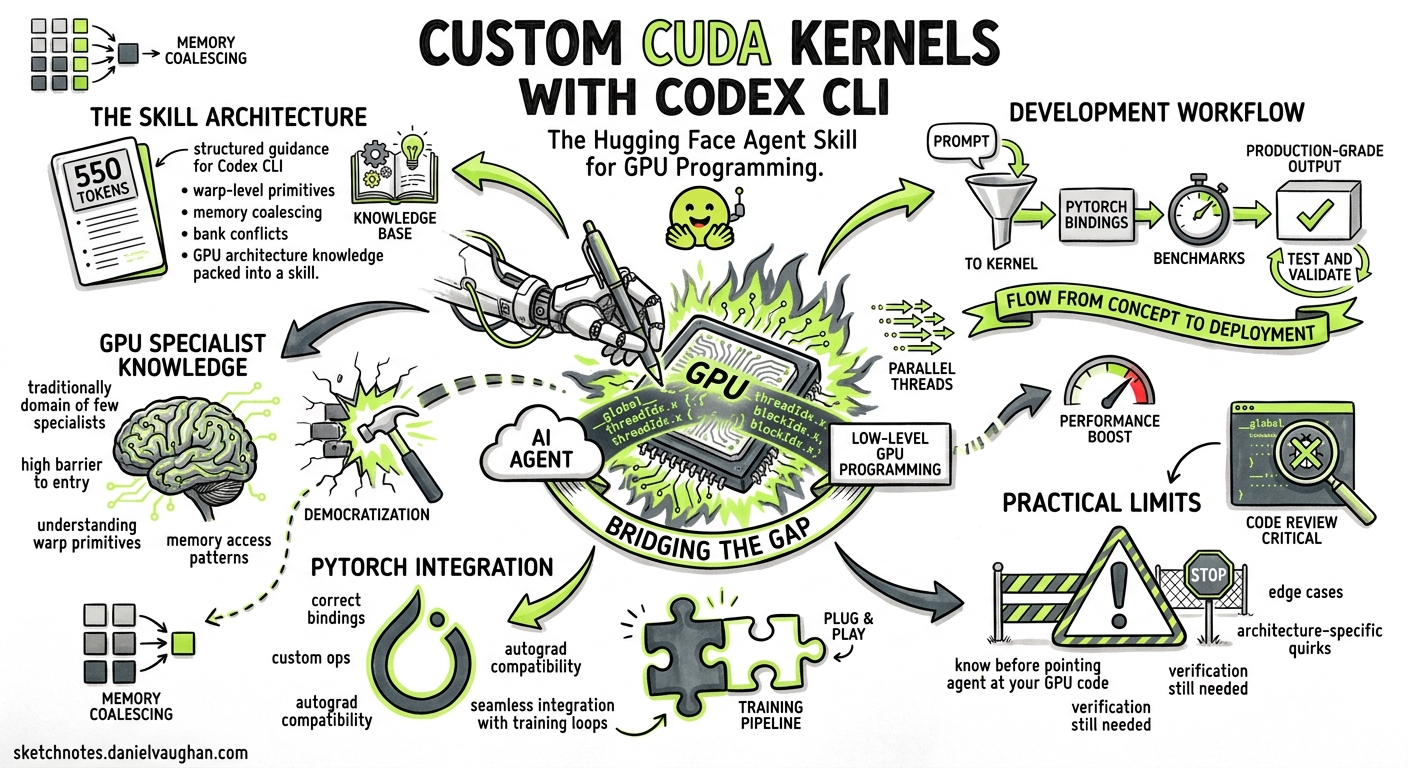
Writing custom CUDA kernels has traditionally been the domain of a small cadre of GPU specialists. The barrier is high: you need to understand warp-level primitives, memory coalescing, bank conflicts, and the idiosyncrasies of each GPU architecture. Hugging Face’s CUDA kernel agent skill changes the equation — it packages that specialist knowledge into roughly 550 tokens of structured guidance that Codex CLI can read, interpret, and act on to produce production-grade kernels with correct PyTorch bindings and benchmarks 1.
This article walks through the skill’s architecture, how to install and use it with Codex CLI, the development workflow from prompt to published kernel, and the practical limits you should know before pointing an agent at your own GPU code.
The Skill Architecture
The Hugging Face CUDA kernel skill follows the standard agent skill specification adopted by Codex CLI, Claude Code, Cursor, and over 30 other tools 2. It installs into Codex’s skills directory and is automatically discovered at session start.
Installation
pip install git+https://github.com/huggingface/kernels.git#subdirectory=kernels
kernels skills add cuda-kernels --codex
The --codex flag targets the $HOME/.agents/skills/ directory where Codex CLI scans for user-scoped skills 3. Alternative flags (--claude, --opencode, --dest) support other agent runtimes, reflecting the cross-tool portability of the SKILL.md specification 4.
What Gets Installed
The skill directory contains more than a prompt file:
.agents/skills/cuda-kernels/
├── SKILL.md # ~550 tokens of core guidance
├── scripts/
│ ├── benchmark_example.py # End-to-end pipeline benchmark
│ ├── benchmark_rmsnorm.py # Isolated kernel micro-benchmark
│ ├── ltx_kernel_injection_example.py # Diffusers integration pattern
│ ├── transformers_injection_example.py # Transformers integration pattern
│ └── huggingface_kernels_example.py # Kernel Hub integration
└── references/
├── h100-optimization-guide.md
├── a100-optimization-guide.md
├── t4-optimization-guide.md
├── kernel-templates.md
├── diffusers-integration.md
├── transformers-integration.md
├── huggingface-kernels-integration.md
└── troubleshooting.md
The references/ directory is the key differentiator from a naive prompt. Each GPU architecture guide encodes compute capability, theoretical bandwidth, shared memory sizes, and block sizing strategies specific to that hardware 1. Codex CLI uses progressive disclosure: the SKILL.md loads first (~550 tokens), and deeper references load on demand as the agent works through the task 3.
The Development Workflow
Once installed, the workflow runs from a single prompt through to a publishable kernel. The agent handles every step.
flowchart LR
A[Prompt] --> B[Architecture Selection]
B --> C[CUDA Source Generation]
C --> D[PyTorch Bindings]
D --> E[build.toml Config]
E --> F[Benchmark Scripts]
F --> G[Validation]
G --> H[Hub Publishing]
Prompting Codex
Focused prompts produce the best results:
codex "Build a vectorised RMSNorm kernel for H100 targeting the Qwen3-8B model in transformers."
The agent reads the skill, selects H100-specific parameters (compute capability 9.0, 3,350 GB/s theoretical bandwidth), generates vectorised CUDA source with BF16 memory access patterns, writes PyTorch C++ bindings, configures build.toml, and creates benchmark scripts 1.
Generated Project Structure
The output follows the kernel-builder layout that the Hugging Face Hub expects 5:
examples/qwen3_8b/
├── kernel_src/
│ └── rmsnorm.cu # Vectorised CUDA kernel
├── torch-ext/
│ ├── your_kernels/__init__.py
│ └── torch_binding.cpp # PyTorch C++ bindings
├── benchmark_rmsnorm.py # Micro-benchmark script
├── build.toml # kernel-builder configuration
├── setup.py
└── pyproject.toml
The build.toml Format
The build configuration targets specific GPU architectures:
[general]
name = "qwen3_kernels"
backends = ["cuda"]
[torch]
src = ["torch-ext/torch_binding.cpp"]
[kernel.rmsnorm]
backend = "cuda"
src = ["kernel_src/rmsnorm.cu"]
depends = ["torch"]
cuda-capabilities = ["9.0"]
The cuda-capabilities field maps to NVIDIA compute capabilities: 9.0 for H100, 8.0 for A100, 7.5 for T4 1. Multiple values produce multi-architecture builds.
Performance: What the Agents Actually Produce
Hugging Face tested the skill against two real targets: Lightricks LTX-Video (a diffusers pipeline) and Qwen3-8B (a transformers model). Both ran on H100 80GB with BFloat16 precision 1.
Kernel-Level Speedups
The agent-generated RMSNorm kernel for Qwen3-8B achieved consistent speedups over PyTorch’s native implementation:
| Sequence Length | Custom (ms) | PyTorch (ms) | Speedup |
|---|---|---|---|
| 128 tokens | 0.040 | 0.062 | 1.58x |
| 1024 tokens | 0.037 | 0.071 | 1.90x |
| 4096 tokens | 0.071 | 0.150 | 2.12x |
| 8192 tokens | 0.109 | 0.269 | 2.47x |
Average: 1.94x speedup, reaching 22.3% of H100 theoretical bandwidth 1. The scaling pattern — faster relative gains at longer sequences — reflects proper vectorised memory access that amortises launch overhead.
End-to-End Pipeline Impact
For LTX-Video (49 frames, 30 diffusion steps), the kernel contribution was more modest but still meaningful:
| Configuration | Time (s) | Speedup |
|---|---|---|
| Baseline | 2.87 | 1.00x |
| Agent kernels | 2.70 | 1.06x |
Baseline + torch.compile |
2.14 | 1.34x |
Agent kernels + torch.compile |
2.01 | 1.43x |
RMSNorm accounts for roughly 5% of total compute in a diffusion pipeline, so the 6% end-to-end gain aligns with expectations 1. The compound effect with torch.compile is notable — the agent generates kernels that register correctly as custom PyTorch operators, meaning the compiler can optimise around them.
Publishing to the Hugging Face Kernels Hub
The kernel-builder Nix flake handles cross-compilation for every PyTorch/CUDA variant 5:
nix flake update
nix run .#build-and-copy -L
Then push to the Hub:
huggingface-cli repo create your-org/qwen3-rmsnorm --type model
huggingface-cli upload your-org/qwen3-rmsnorm ./build
Consumers load the kernel with zero compilation:
from kernels import get_kernel
rmsnorm = get_kernel("your-org/qwen3-rmsnorm")
The get_kernel() function auto-detects the user’s Python, PyTorch, and CUDA versions and downloads the matching pre-compiled binary 5. No build toolchain required on the consumer side.
Codex CLI Considerations
Sandbox Limitations
Codex CLI’s default sandbox does not pass through GPU access 6. The kernel generation step — writing .cu files, bindings, and build configuration — runs entirely within the sandbox. Compilation and benchmarking require either:
- Running Codex in
full-automode on a GPU-equipped machine with appropriate sandbox configuration - Generating the code with Codex, then compiling and benchmarking outside the agent session
For CI integration, codex exec can generate the kernel project non-interactively, with a separate GPU-enabled job handling the build and benchmark steps 7.
Model Selection
GPU kernel development benefits from frontier reasoning. GPT-5.5 is the recommended model for CUDA work, particularly for complex optimisation decisions around memory access patterns, warp shuffles, and shared memory sizing 8. For simpler modifications or parameter sweeps, GPT-5.4-mini at 30% credit cost provides adequate results 8.
AGENTS.md for Kernel Repositories
If you maintain a kernel repository, encode your conventions in AGENTS.md:
# Kernel Development Conventions
- All kernels must target H100 (compute capability 9.0) as primary architecture
- Use BFloat16 precision unless the operation requires FP32 accumulation
- Every kernel must include a micro-benchmark against PyTorch baseline
- Follow kernel-builder project layout for Hub compatibility
- Run checkpatch-equivalent style checks on any C++ binding code
This ensures Codex applies your standards even when working with the CUDA kernel skill’s broader guidance 3.
The AMD Driver Precedent
The CUDA kernel skill is not the only systems-programming success story. In May 2026, developer Jihong Min submitted the prom21-xhci driver to the Linux kernel mailing list — a temperature sensor driver for AMD Promontory 21 chipsets (AM5, 600/800 series) — created in part with Codex GPT-5.5 9. The driver integrates with the HWMON subsystem and is currently under review. ⚠️ The driver’s review status may have changed since the Phoronix report on 10 May 2026.
These examples point in the same direction: agent-assisted development is reaching into domains — GPU kernels, kernel drivers — where correctness requirements are absolute and the talent pool is shallow. The skill-based approach works because it encodes domain expertise as structured context rather than relying on the model’s training data alone.
Current Limitations
- No GPU passthrough in sandbox: Kernel compilation and benchmarking cannot run inside Codex CLI’s default sandboxed environment 6
- Architecture-specific tuning: The skill includes guides for H100, A100, and T4 only; other architectures (L40S, RTX 4090, Blackwell) require manual reference additions
- Kernel scope: The demonstrated kernels (RMSNorm, RoPE, GEGLU, AdaLN) are relatively straightforward compute-bound operations; attention kernels with complex memory access patterns push the limits of what agent-generated code can match against hand-tuned implementations like FlashAttention 1
- Nix dependency: The cross-compilation publishing workflow requires a Nix installation, which adds friction for teams not already using it 5
Conclusion
The Hugging Face CUDA kernel skill demonstrates that agent skills can encode genuine systems-level expertise compactly enough for Codex CLI to produce working, benchmarkable, distributable GPU code. The 1.6–2.5x speedups on RMSNorm are real and reproducible. The key insight is architectural: domain knowledge lives in the skill’s reference documents, not in the model’s weights, making the system updatable as new GPU architectures ship without waiting for model retraining.
For Codex CLI practitioners, the takeaway is practical: install the skill, point Codex at your model’s bottleneck operation, and let the agent produce a kernel project you can validate. The Hub handles distribution. The model handles the CUDA. You handle the review.
Citations
-
Hugging Face, “Custom Kernels for All from Codex and Claude,” Hugging Face Blog, February 2026. https://huggingface.co/blog/custom-cuda-kernels-agent-skills ↩ ↩2 ↩3 ↩4 ↩5 ↩6 ↩7 ↩8
-
Anthropic, “Agent Skills Open Standard,” December 2025; adopted by 32+ tools including Codex CLI, Claude Code, Cursor, and GitHub Copilot. https://www.paperclipped.de/en/blog/agent-skills-open-standard-interoperability/ ↩
-
OpenAI, “Agent Skills – Codex,” OpenAI Developers Documentation. https://developers.openai.com/codex/skills ↩ ↩2 ↩3
-
Linux Foundation, “Agentic AI Foundation (AAIF),” founded December 2025 with Anthropic, OpenAI, and Block; grew to 146 member organisations by February 2026. https://agents.md/ ↩
-
Hugging Face, “From Zero to GPU: A Guide to Building and Scaling Production-Ready CUDA Kernels,” Hugging Face Blog. https://huggingface.co/blog/kernel-builder ↩ ↩2 ↩3 ↩4
-
OpenAI, “Agent approvals & security – Codex,” OpenAI Developers Documentation. https://developers.openai.com/codex/agent-approvals-security ↩ ↩2
-
OpenAI, “Non-interactive mode – Codex,” OpenAI Developers Documentation. https://developers.openai.com/codex/noninteractive ↩
-
OpenAI, “Models – Codex,” OpenAI Developers Documentation. https://developers.openai.com/codex/models ↩ ↩2
-
Phoronix, “OpenAI’s Coding Agent Helped Create A New AMD Temperature Driver For Linux,” 10 May 2026. https://www.phoronix.com/news/AMD-Prom21-xHCI-Temp-Driver ↩