Adapting Agile Ceremonies for AI Coding Agents: Sprint Planning, Standups, and Retros
Adapting Agile Ceremonies for AI Coding Agents: Sprint Planning, Standups, and Retros
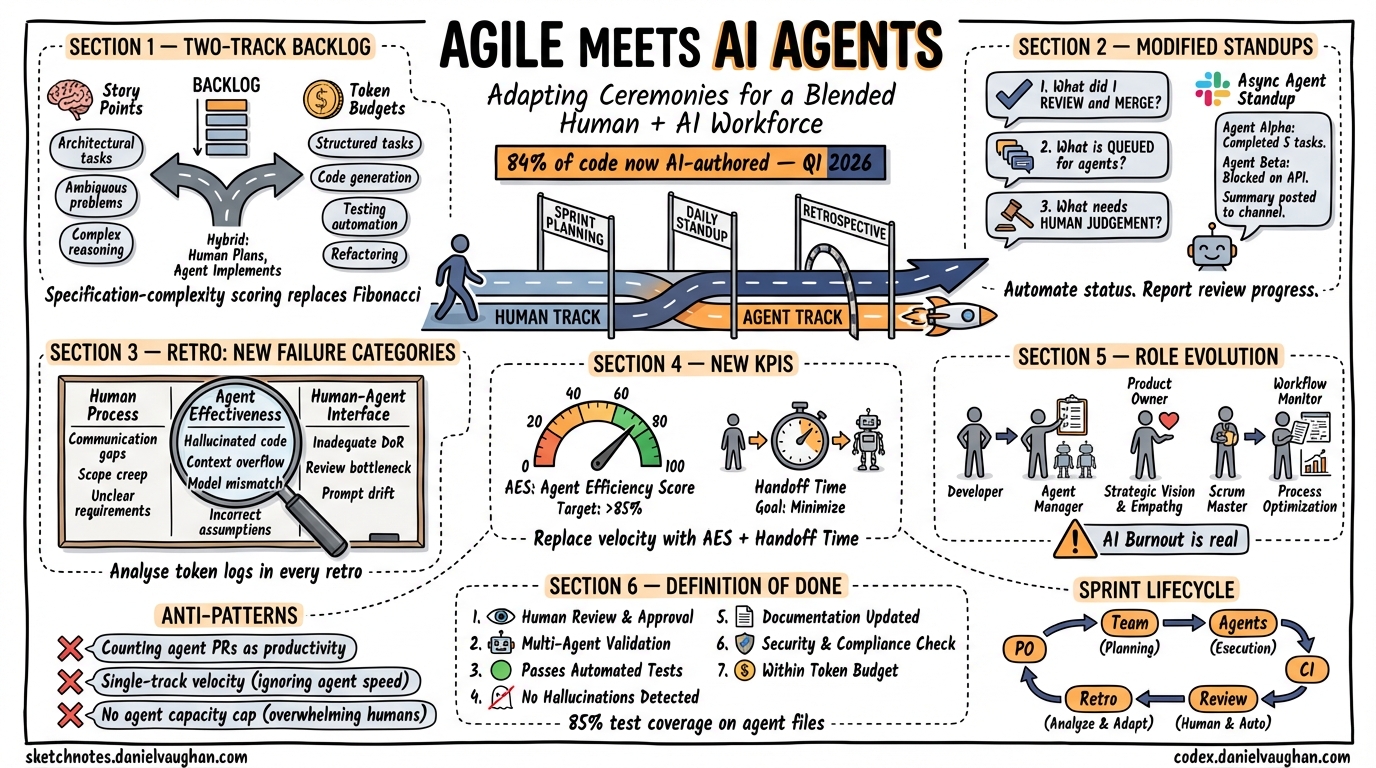
When autonomous coding agents handle 40–60% of implementation work, the standard Scrum playbook breaks down. Story points lose their meaning, standups become status theatre, and retrospectives miss the most important failure modes. The Q1 2026 AI Velocity Report found that 84% of code at early-adopter firms is now AI-authored, up from 51% in Q4 2025, with median cycle times dropping 24% 1. This article examines how to adapt each core Agile ceremony for teams where Codex CLI, Claude Code, and similar agents are first-class contributors — not just tools that developers happen to use.
The Core Problem: Context Transfer
Every Agile ceremony exists to solve one problem: context transfer 2. Standups transfer status. Sprint planning transfers intent. Retros transfer learning. Human ceremonies evolved around human bandwidth limitations — short attention spans, lossy memory, and the overhead of switching between tasks.
AI agents have different constraints. They do not get tired, but they lose context between sessions 2. They execute rapidly, but they cannot negotiate scope with stakeholders. They produce code at scale, but they cannot self-assess whether the code solves the right problem. Adapting ceremonies means redesigning context transfer for a workforce that is part-human, part-machine.
Sprint Planning: From Story Points to Task Routing
Why Story Points Fail for Agents
Story points were designed to measure human cognitive load, uncertainty, and fatigue 3. An autonomous agent running on gpt-5.4 does not experience cognitive fatigue, runs around the clock, and processes structured tasks with near-constant throughput 3. Assigning story points to agent work conflates two fundamentally different capacity models. As Scrum.org’s evidence-based management framework now argues, if a team’s velocity jumps from 50 to 5,000 in one sprint after adopting AI tools, they have not actually delivered 100× more value — the metric has simply stopped measuring anything useful 4.
The 18th State of Agile Report found that 84% of teams use AI somewhere in their workflow, but only 41% have integrated it into their ceremonies in a coordinated way 5. Most teams are still bolting agent output onto human-shaped processes.
The Two-Track Backlog
Before sprint planning begins, segment the backlog into two tracks:
flowchart TD
A[Product Backlog] --> B{Task Classification}
B -->|Structured, well-specified| C[Agent Track]
B -->|Ambiguous, architectural| D[Human Track]
B -->|Hybrid| E[Human Plans → Agent Implements]
C --> F[Token Budget Estimation]
D --> G[Story Point Estimation]
E --> H[Split: Human SP + Agent Tokens]
F --> I[Sprint Commitment]
G --> I
H --> I
Agent Track tasks are well-specified, have clear acceptance criteria, and map to capabilities the agent demonstrably handles: refactoring, test generation, boilerplate implementation, documentation updates, and data transformation 6. These tasks get token budget estimates rather than story points — forecast the API token consumption and compute time, not human effort 3. Some teams are adopting specification-complexity scoring instead of effort-based Fibonacci: since code generation time is now near-zero, the point value reflects the verification effort required rather than the implementation effort 6.
Human Track tasks retain traditional story point estimation: architectural decisions, security sign-offs, stakeholder negotiations, and strategic “why” decisions 3.
Hybrid tasks — the most common category — split into a human planning phase and an agent implementation phase. The human writes the technical design; the agent executes it.
Definition of Ready for Agent Tasks
A standard user story is insufficient context for an agent. The Definition of Ready for agent-routed tasks must include 3:
- Data schemas and type definitions the agent will touch
- Negative constraints — what the agent must not change
- Verification commands — how to confirm the task is done (e.g.,
npm test,cargo clippy) - Context file references — which
AGENTS.mdorCLAUDE.mdsections apply 2 - API documentation links for any external integrations
In Codex CLI terms, this maps directly to the four-element prompt structure from OpenAI’s best practices: goal, context, constraints, and done criteria 7.
Capacity Planning: The Review Bottleneck
The critical constraint is not agent throughput — it is human review bandwidth 3. An agent can produce 50 pull requests in a day; a four-person team can review perhaps 15 thoroughly. Plan sprint capacity so that agent output never outpaces human review:
Agent capacity = min(compute_budget, human_review_bandwidth × review_ratio)
Teams that ignore this create a growing queue of unreviewed PRs, which is worse than having no agent at all — it is invisible technical debt accumulating behind a facade of velocity 3.
Standups: Reporting on Agent Work
The Problem with Traditional Standups
A standard “what did you do yesterday, what will you do today, any blockers” format fails when half the work happened autonomously overnight. Developers end up either ignoring agent output or spending the entire standup narrating what their agents did.
A Modified Standup Template
Structure standups around three questions per developer:
- What did I review and merge? — The human’s primary output is now validated, merged agent work.
- What is queued for agent execution? — Tasks dispatched to Codex CLI automations 8 or background worktrees.
- What needs human judgement? — Blockers that require architectural decisions, scope negotiation, or security review.
For the agent work itself, surface status through tooling rather than verbal updates. Codex CLI’s automation panel 8 and the codex-plugin-cc status commands 9 can generate a machine-readable summary:
# Quick status of overnight agent work
codex --status --format=summary
# Or via the cross-provider bridge in Claude Code
/codex:status
Async Agent Standups
For distributed teams, consider an async agent standup — a daily automated summary posted to Slack or your project management tool. This is a natural extension of Codex CLI’s automation feature, which supports scheduled tasks running in background worktrees 8:
# Example: Codex automation that posts daily agent status
[automations.daily-status]
schedule = "0 8 * * 1-5"
prompt = "Summarise all PRs opened by agents in the last 24 hours. Group by status: merged, pending review, changes requested, failed CI."
Retrospectives: New Failure Categories
Standard Retro Formats Miss Agent Failures
A “what went well / what didn’t / action items” retro captures human process failures but misses the failure modes unique to agent-assisted development. Teams need additional categories:
flowchart LR
A[Retro Categories] --> B[Human Process]
A --> C[Agent Effectiveness]
A --> D[Human–Agent Interface]
B --> B1[Communication gaps]
B --> B2[Scope creep]
C --> C1[Hallucinated code]
C --> C2[Context window overflow]
C --> C3[Model selection mismatch]
D --> D1[Inadequate DoR]
D --> D2[Review bottleneck]
D --> D3[Prompt drift]
Agent-Specific Retro Questions
Add these to your standard retro format:
- Prompt quality: Did poorly specified tasks cause agent rework? Track the ratio of first-attempt acceptance to revision cycles.
- Model routing: Were expensive flagship models (gpt-5.4) used for tasks that gpt-5.4-mini could handle? Codex CLI’s dynamic model routing and the
/fastcommand 10 make this a tuneable parameter, not a fixed cost. - Context drift: Did long-running agent sessions produce increasingly off-target output? This signals the need for session boundaries or subagent decomposition 11.
- Review fatigue: Did reviewers approve agent PRs without adequate scrutiny? Track defect escape rate from agent-generated code specifically.
- AGENTS.md gaps: Did the agent repeatedly make mistakes that a better
AGENTS.mdwould have prevented? TreatAGENTS.mdupdates as retro action items 7.
Velocity Tracking: Blended Metrics
Traditional velocity charts become misleading when agent throughput inflates the numbers. Track two separate velocity streams:
| Metric | Human Track | Agent Track |
|---|---|---|
| Throughput | Story points completed | Tasks completed + tokens consumed |
| Quality | Defects per SP | Defects per task, first-pass acceptance rate |
| Cost | Developer hours | API spend (USD) |
| Bottleneck | Context switching | Review queue depth |
Report them together on the same sprint dashboard, but never sum them into a single velocity number. A sprint where “velocity doubled” means nothing if the entire increase came from agent-generated boilerplate that required zero architectural thought.
Emerging KPIs: Agent Efficiency Score and Handoff Time
Scrum.org’s evidence-based management framework proposes two metrics purpose-built for the agent era 4:
Agent Efficiency Score (AES) measures autonomous reliability: Tasks Completed Autonomously / (Total Tasks Assigned + (Human Interventions × Complexity Penalty)). High AES (80–100) means the agent performs with minimal human rework; low AES (<50) means extensive human intervention was needed. Track this per task category — an agent might score 95 on test generation but 40 on architectural refactoring, which directly informs backlog segmentation.
Human–Agent Handoff Time measures the elapsed time between an agent signalling “stuck” and a human successfully resuming the work 4. This reveals the context-switching tax that is now the primary bottleneck in agent-augmented sprints. If handoff time is high, the team needs better AGENTS.md files, clearer failure escalation patterns, or dedicated “agent triage” rotations during the sprint.
Together, these replace velocity as the planning input: Sprint capacity = f(AES, handoff_time, review_bandwidth) rather than Sprint capacity = historical_velocity ± variance.
Role Evolution in Agent-Augmented Scrum
The three Scrum roles do not disappear, but their centre of gravity shifts 12:
- Developers transition from code writers to agent managers and code reviewers. The primary skill becomes specification quality — writing prompts,
AGENTS.mdfiles, and Definition of Ready artefacts that produce correct agent output on the first attempt. - Product Owners remain exclusively human. User empathy, stakeholder negotiation, and strategic prioritisation cannot be delegated to agents. The PO’s new responsibility is ensuring that backlog items include enough structured context for agent routing.
- Scrum Masters shift from facilitating human collaboration to monitoring agentic workflows: API rate limits, token budgets, review queue depth, and agent confidence scores. A Scrum Master who cannot read a Codex CLI session log is as ineffective as one who cannot read a burndown chart.
The AI-augmented Scrum framework also introduces the concept of “AI burnout” — the cognitive exhaustion humans experience from reviewing massive volumes of AI-generated code 12. This is a real impediment that surfaces in retros and must be managed through review rotation, automated pre-checks (hooks, linters, CI), and sensible agent output caps per sprint.
Definition of Done: The Agent Extension
Extend your existing Definition of Done with agent-specific criteria:
- Code review by a human — Agent-generated code requires the same review standard as human code. No exceptions.
- Cross-provider review — For critical paths, use
codex-plugin-cc’s adversarial review 9 to have a second model review the first model’s output. - CI green — Agents must run verification commands before submitting. Codex CLI supports this via
AGENTS.mdverification sections 7 and PostToolUse hooks that run static analysis after every file modification. - Zero-hallucination verification — Verify the agent has not introduced libraries, APIs, or configuration that were hallucinated rather than real 13. Automated dependency audits (
npm audit,pip-audit) should run as part of the CI gate. - Context documented — Any architectural decisions made during implementation are captured in comments or ADRs, not buried in agent chat logs.
- Security scan passed — Agent-generated code must pass the same security scanning (SAST, dependency checks) as human code. Minimum 85% test coverage on agent-modified files 6.
- Token spend within budget — The task’s actual API spend must not exceed the sprint planning estimate by more than a defined threshold (e.g., 150%). Overruns are retro action items, not silent costs.
Putting It Together: A Sprint Lifecycle with Agents
sequenceDiagram
participant PO as Product Owner
participant Team as Dev Team
participant Agent as Codex CLI Agents
participant CI as CI Pipeline
PO->>Team: Refined backlog with DoR
Team->>Team: Sprint planning: classify & estimate
Team->>Agent: Dispatch agent-track tasks
Agent->>CI: Submit PRs with verification
CI->>Team: CI results + PR queue
Team->>Team: Daily standup (review focus)
Team->>Agent: Reroute failed tasks with updated context
Agent->>CI: Resubmit with corrections
Team->>Team: Sprint review: demo merged work
Team->>Team: Retro: human + agent + interface categories
Team->>PO: Updated AGENTS.md as retro action item
Common Anti-Patterns
- Counting agent PRs as developer productivity — This incentivises dispatching trivial work to inflate metrics. Measure merged-and-deployed PRs, not opened PRs 1.
- Skipping review for “simple” agent changes — Agent errors cluster in edge cases and naming, exactly the areas humans skip when reviewing “simple” diffs.
- Single-track velocity — Blending human and agent throughput into one number makes sprint planning unreliable. The Scrum.org EBM framework is explicit: retire velocity in favour of Agent Efficiency Score 4.
- Agent standup theatre — Developers narrating agent logs verbally wastes everyone’s time. Automate status reporting.
- Ignoring token economics — A sprint that “completes” 200% more stories but triples API spend is not an improvement without ROI analysis.
- Running retros without token logs — A retrospective that does not analyse agent session logs, token consumption, and model routing decisions is missing half the data. Treat agent workflow debugging as a first-class retro activity 12.
- No agent capacity cap — Dispatching unlimited work to agents overwhelms the review queue. Set a per-sprint ceiling based on the team’s proven review throughput.
Conclusion
Agile ceremonies are not obsolete in the age of AI agents — they are more important than ever, because the context transfer problem has become harder, not easier. The adaptation is straightforward in principle: separate human and agent capacity models, redesign standups around review rather than implementation, add agent-specific failure categories to retros, and adopt purpose-built metrics like Agent Efficiency Score and Handoff Time that measure what actually matters in a blended workforce.
The Q1 2026 data is clear: teams that manage this transition deliberately — with structured ceremonies, clear role evolution, and honest metrics — see 40–50% faster delivery with fewer defects 1. Teams that bolt agents onto unchanged Scrum rituals see inflated velocity numbers, growing review queues, and invisible technical debt. The ceremonies are the same. The context they transfer has changed.
Citations
-
“AI Velocity Report Q1 2026: Real Delivery Data from 84% AI-Authored Code,” Talk Think Do, talkthinkdo.com, 2026. ↩ ↩2 ↩3
-
Josh Owens, “Your AI Doesn’t Need Better Prompts. It Needs a Sprint Planning Session,” joshowens.dev, 2026. ↩ ↩2 ↩3
-
“How to do Sprint Planning for AI Agents,” Agile Leadership Day India, agileleadershipdayindia.org, March 2026. ↩ ↩2 ↩3 ↩4 ↩5 ↩6 ↩7
-
“From Velocity to ‘Agent Efficiency’: Evidence-Based Management for the AI Era,” Scrum.org, scrum.org, 2026. ↩ ↩2 ↩3 ↩4
-
“AI in Agile Project Management: What’s Actually Working in 2026,” Kollabe, kollabe.com, 2026. ↩
-
“Agentic IDEs: Cut Agile Dev Cycles by 40%,” Agile Leadership Day India, agileleadershipdayindia.org, April 2026. ↩ ↩2 ↩3
-
“Workflows – Codex,” OpenAI Developers, developers.openai.com, 2026. ↩ ↩2 ↩3
-
“Features – Codex CLI,” OpenAI Developers, developers.openai.com, 2026. ↩ ↩2 ↩3
-
Daniel Vaughan, “codex-plugin-cc: OpenAI’s Official Cross-Provider Bridge for Claude Code,” codex-resources, 2026-04-12. ↩ ↩2
-
Daniel Vaughan, “Dynamic Model Routing in Codex CLI,” codex-resources, 2026-04-12. ↩
-
“Subagents – Codex,” OpenAI Developers, developers.openai.com, 2026. ↩
-
“Run Scrum When Half Your Team is AI Agents,” Agile Leadership Day India, agileleadershipdayindia.org, March 2026. ↩ ↩2 ↩3
-
“The State of AI Coding Agents (2026): From Pair Programming to Autonomous AI Teams,” Dave Patten, medium.com, March 2026. ↩