The Great Convergence: Why Every AI Coding Agent Now Runs the Same Pipeline
The Great Convergence: Why Every AI Coding Agent Now Runs the Same Pipeline
I have been tracking over a dozen AI coding agents for months now — OpenAI Codex CLI, Anthropic Claude Code, Google Jules, Cursor, GitHub Copilot Agent, Windsurf, Amazon Q Developer, JetBrains Junie, Goose, Aider, OpenCode, Cline, Roo Code — and a pattern has become impossible to ignore. Despite different companies, different models, different interfaces, and different business models, they have all converged on the same fundamental execution pipeline.
This is not a coincidence. It is the natural result of a shared problem space with hard constraints. This article maps out exactly what that shared pipeline looks like, why it emerged, what still differentiates agents, and what it means for the future.
The Universal Pipeline
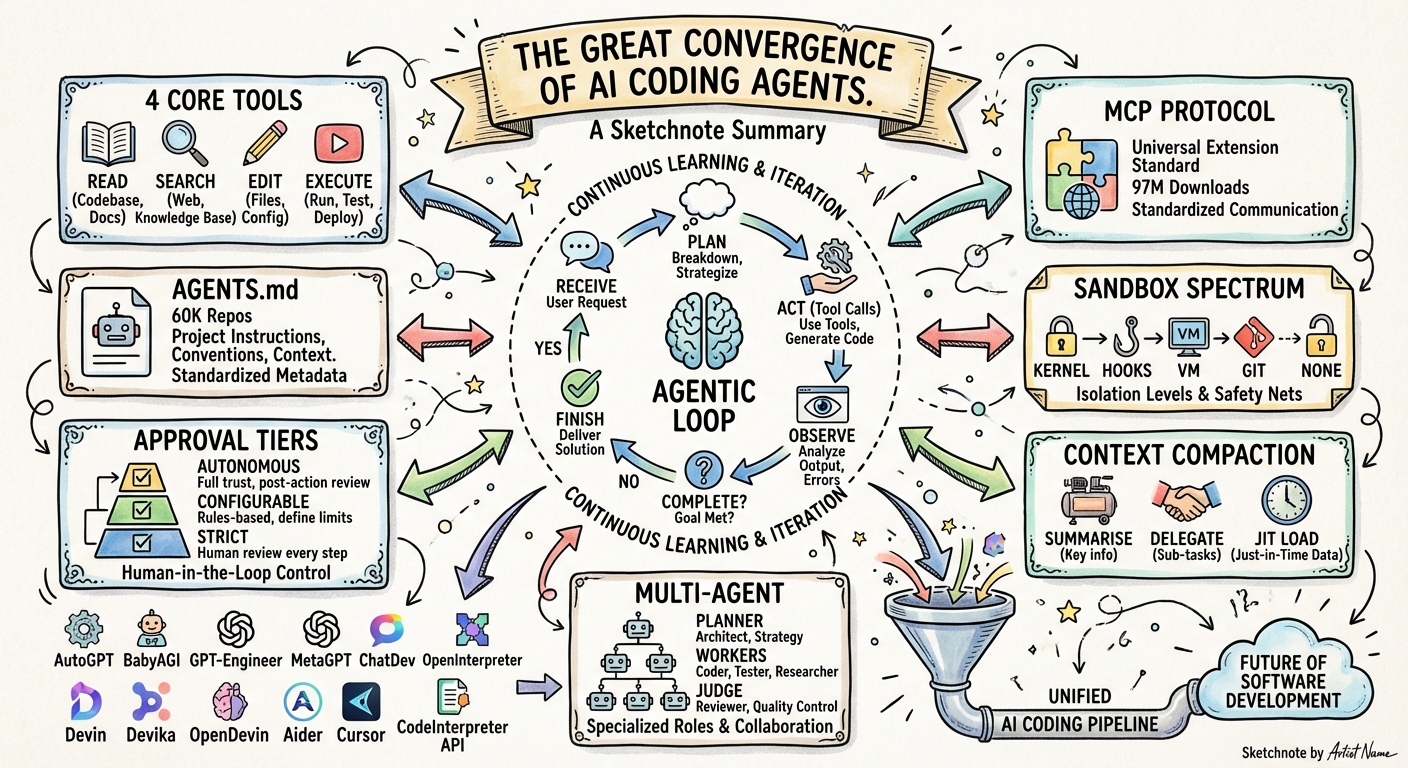
An academic taxonomy paper analysing 13 coding agent source codes confirmed what practitioners have been feeling: seven of thirteen agents use sequential ReAct as their core control primitive, and the remaining six use variations that still follow the same observe-act-reflect cycle.1
Here is the pipeline that every major coding agent now implements:
graph TD
A["1. Receive & Contextualise\n(prompt + system instructions +\nproject files + conversation history)"] --> B["2. Plan\n(evaluate state, determine\nstrategy, select tools)"]
B --> C["3. Act via Tool Calls\n(read / search / edit / execute)"]
C --> D["4. Observe Results\n(tool output, errors,\ntest results)"]
D --> E{"5. Task\nComplete?"}
E -->|No| B
E -->|Yes| F["6. Return Response\n(summary + artifacts)"]
Claude Code’s Agent SDK documentation describes it plainly: “Claude evaluates your prompt, calls tools to take action, receives the results, and repeats until the task is complete.”2 Codex CLI’s app-server protocol encodes the same cycle through its Thread → Turn → Item hierarchy, where each Turn is one complete iteration of the loop and each Item is an atomic action within it.3 Cursor, Copilot, Jules, Windsurf — the same loop, different wrappers.
This is the agentic coding loop, and it is now the industry standard.
The Seven Convergence Points
The pipeline convergence goes far deeper than “they all have a loop.” There are seven specific architectural primitives where agents have landed on nearly identical designs.
1. The Four Core Tool Categories
Despite ranging from zero to thirty-seven registered tools, every LLM-driven coding agent implements four core capabilities:1
| Category | What It Does | Example Tools |
|---|---|---|
| Read | Inspect code and project state | Read, cat, View |
| Search | Find files and content | Glob, Grep, ripgrep, tree-sitter AST |
| Edit | Modify source files | Edit (str_replace), Write, patch |
| Execute | Run commands | Bash, shell, terminal |
The edit format has standardised around string replacement with old_str/new_str, used by five of thirteen agents studied. This proved more reliable than line-number-based editing because LLMs can reason about textual patterns more accurately than numerical offsets.1
2. MCP as the Universal Extension Protocol
The Model Context Protocol has crossed 97 million monthly SDK downloads and has been adopted by every major AI provider.4 In December 2025, Anthropic donated MCP to the Agentic AI Foundation under the Linux Foundation, co-founded with Block and OpenAI.5
The practical impact: if you build an MCP server for your database, your internal API, or your deployment pipeline, it works with Codex, Claude Code, Cursor, Copilot, Windsurf, Cline, Gemini Code Assist, and a dozen more. The extension model has converged completely.
graph LR
subgraph Agents["Any Coding Agent"]
Agent["Agent Loop"]
end
subgraph MCP["MCP Servers (Universal)"]
DB["Database"]
Deploy["Deployment"]
Monitor["Monitoring"]
Custom["Your Tools"]
end
Agent <-->|"MCP Protocol\n(Tools, Resources, Prompts)"| DB
Agent <-->|MCP| Deploy
Agent <-->|MCP| Monitor
Agent <-->|MCP| Custom
3. Project Instruction Files
AGENTS.md has become the open standard for project-level agent instructions, now maintained by the Agentic AI Foundation and supported by Codex CLI, Copilot, Cursor, Gemini CLI, Windsurf, Aider, Amp, Roo Code, Zed, and Warp. Over 60,000 GitHub repositories include one.6 Claude Code has its own five-layer CLAUDE.md system but also reads AGENTS.md as a fallback. Teams commonly symlink one to the other.
The convergence here is striking: every agent now expects to find machine-readable project context — coding standards, test commands, architectural constraints — in a markdown file at the repository root. The filename differs, but the concept is identical.
4. Sandboxed Execution
Every agent that runs shell commands must decide how to isolate them. The implementations vary, but the design space has collapsed to a handful of approaches:
| Strategy | Agents |
|---|---|
| OS kernel-level (Seatbelt, Landlock, seccomp, bubblewrap) | Codex CLI |
| Application-layer hooks (lifecycle event interception) | Claude Code (17 hook events) |
| Container/VM isolation | Jules (Google Cloud VM), Codex cloud, SWE-agent, OpenHands |
| Git-based checkpoints (revert on failure) | Cline, Kilo Code |
| No sandboxing (user trust model) | Gemini CLI, Aider, OpenCode |
The spectrum runs from “kernel enforced” to “trust the user,” but every serious agent has had to make an explicit architectural decision about this — and most have moved toward some form of isolation.7
5. Approval Workflows
The human-in-the-loop spectrum has converged on three tiers:
graph LR
Strict["Strict\n(approve every action)"] --> Configurable["Configurable\n(approve consequential actions)"] --> Autonomous["Autonomous\n(approve nothing)"]
Strict -.- Cline["Cline\nRoo Code"]
Configurable -.- ClaudeCode["Claude Code\nCodex CLI\nCopilot\nWindsurf"]
Autonomous -.- Background["CI/CD mode\nCloud exec\nbypassPermissions"]
Cline requires explicit approval for every file change and terminal command. Claude Code and Codex CLI offer configurable modes (suggest/auto-accept/full-auto). In CI/CD pipelines, every agent that supports headless execution has a “just run it” mode. The approval primitives — accept, decline, cancel, accept-with-amendment — are remarkably similar across implementations.8
6. Context Compaction
Every agent faces the same constraint: context windows are finite, coding sessions are not. The solutions have converged on a shared toolkit:
- Automatic summarisation: When context approaches the limit, compress older history while preserving recent exchanges (Claude Code, Codex CLI, OpenDev)
- Subagent delegation: Spawn child agents with fresh context for subtasks; only the summary returns to the parent (Claude Code Task tool, Codex cloud exec)
- Repository maps: AST-aware project summaries fitted to the token budget (pioneered by Aider with tree-sitter + PageRank)
- Just-in-time loading: The industry has shifted from pre-embedding entire codebases to “agentic search” — using grep and file reads on demand9
The specific algorithms differ (Codex uses a two-phase extraction-consolidation pipeline backed by SQLite; Claude Code uses PreCompact hooks and rolling summaries), but the strategic response is the same everywhere.
7. Multi-Agent Orchestration
Mike Mason documented in January 2026 how Claude Code, Cursor, Devin, OpenHands, and Aider all independently converged on hierarchical orchestration with Planners, Workers, and Judges — after initial approaches using peer agents with locking or optimistic concurrency proved inefficient.10
The pattern is now standard:
- A planner decomposes the task
- Workers execute subtasks (often in parallel, often in isolated git worktrees)
- A reviewer/judge validates the output
Codex does this with cloud exec dispatching up to six parallel workers. Claude Code does it with the Task tool spawning subagents. Roo Code does it with mode-based routing (Architect → Code → Debug). Different mechanisms, same architecture.
What Still Differentiates Agents
If the pipeline has converged, what is left to compete on? Quite a lot, as it turns out. The differentiators have shifted from what agents do to how they do it:
| Dimension | Range |
|---|---|
| Model ecosystem | Single-vendor (Claude Code: Anthropic only) vs. multi-model (Cursor: GPT-5.3, Sonnet 4.5, Gemini 3 Pro; OpenCode: 75+ models) |
| Context window | 1M tokens (Codex/GPT-5.4) vs. 200K tokens (Claude Code/Opus 4.6) |
| Interface | Terminal-native (Claude Code, Aider) vs. IDE-embedded (Cursor, Copilot) vs. async cloud (Jules, Codex cloud) vs. desktop app (Codex Scratchpad) |
| Safety philosophy | Kernel sandbox vs. hooks vs. per-action approval vs. none |
| Pricing | Subscription ($15-20/mo) vs. usage-based (per-token) vs. free/OSS |
| Deployment | Local-only vs. hybrid local+cloud vs. cloud-first |
| Enterprise governance | Amazon Bedrock Guardrails, Qodo review agents, Claude Code hooks vs. minimal governance |
The competition has moved up the stack. The pipeline is settled; the policy layer on top of it is where the action is.
Why Convergence Was Inevitable
Three forces drove every agent to the same design:
1. The LLM constraint. Tool-calling is how modern LLMs interact with the world. Every model provider (OpenAI, Anthropic, Google) converged on the same function-calling interface. Once your model speaks “tools,” your agent loop writes itself: call the model, execute the tools it requests, feed back results, repeat.
2. The developer workflow constraint. Software development has a fixed set of primitive operations — read files, search code, edit files, run commands, run tests. There is no fifth operation. Any agent that wants to be useful for coding must implement these four, which means the tool surface converges.
3. The safety constraint. The moment you let an LLM run shell commands, you need sandboxing and approval workflows. The design space for “how do you let an AI execute code safely” is surprisingly small, and every team explored it independently and landed on the same options.
4. The economics constraint. Kent Beck captures this in an April 2026 Pragmatic Engineer interview: “the whole landscape of what’s cheap and what’s expensive has all just shifted.”11 When code generation becomes near-free, the expensive operations become verification, design, and context engineering. Every agent team independently discovered this — which is why they all converged on the same verification primitives (test gates, approval workflows, hook-based quality enforcement) rather than competing on generation speed alone.
Convergence is not a failure of imagination. It is evidence that the problem is well-defined.
Enterprise Evidence: Four Companies, Same Architecture
If the convergence thesis seems abstract, consider the concrete evidence from production. LangChain’s Open SWE framework, released in April 2026, was built by studying internal coding agents at three companies: Stripe (Minions), Ramp (Inspect), and Coinbase (Cloudbot). Each team built their agent independently — Stripe forked Goose, Ramp composed on OpenCode, Coinbase built from scratch. Yet all three converged on the same architectural primitives:12
| Primitive | Stripe (Minions) | Ramp (Inspect) | Coinbase (Cloudbot) | Open SWE |
|---|---|---|---|---|
| Foundation | Forked (Goose) | Composed (OpenCode) | Built from scratch | Composed (Deep Agents) |
| Sandbox | AWS EC2 | Modal containers | In-house | Pluggable (Modal, Daytona, Runloop) |
| Tools | ~500 curated | OpenCode SDK | MCPs + Skills | ~15 curated |
| Orchestration | Blueprints | Sessions | Three modes | Subagents + middleware |
Four different companies. Four different starting points. The same destination: isolated execution, curated tool surfaces, subagent delegation, and middleware safety nets. Open SWE’s key design principle — customisation without forking — means sandbox providers, LLM models, tools, triggers, and middleware are all pluggable. Swap any component without rebuilding the core. This is the convergent pipeline made modular.13
The Discipline Layer: Agent Skills
Addy Osmani’s Agent Skills project (10,000+ GitHub stars) represents the next convergence happening on top of the shared pipeline. It encodes senior engineering discipline — drawn from Google’s engineering culture — into a reusable library of 19 skills and 7 commands that work identically across Claude Code, Cursor, and Gemini CLI:14
/spec → /plan → /build → /test → /review → /code-simplify → /ship
The golden rules it enforces — specification before code, testing before merging, measurement before optimisation — are agent-agnostic. They work because every agent underneath runs the same pipeline. Osmani’s insight is pointed: left to their own devices, agents optimise for “done” rather than “correct,” skipping specifications, bypassing tests, and ignoring security reviews. The shared pipeline needs a shared discipline layer, and that layer is converging too — incorporating principles like Hyrum’s Law, Chesterton’s Fence, and Shift Left methodology.
This is the pattern emerging above the pipeline: not just shared mechanics, but shared engineering culture encoded as portable configuration.
What Comes Next
If the pipeline is converged, the next wave of innovation will be in:
- Context engineering — the discipline of optimising what goes into the context window, which has already displaced prompt engineering as the critical skill15
- Verification and trust — automated proof that agent-generated code is correct, moving beyond “run the tests” to formal verification, property-based testing, and mutation testing
- Governance at scale — enterprise policy engines that constrain agent behaviour across teams, projects, and regulatory regimes
- Inter-agent communication — standards like A2A (Google’s Agent-to-Agent protocol) and cross-agent config sync tools (ruler, cc-switch) enabling agents from different vendors to collaborate on the same task16
- Specialisation within the loop — agents that share the pipeline but excel at specific domains (security review, database migration, legacy modernisation, mobile development)
The pipeline is the floor, not the ceiling. Now that everyone has it, the question becomes: what do you build on top?
Related Articles
Several earlier articles in this series explore individual convergence points in depth:
- Agentic Primitives: Codex, Claude, and Gemini — the shared building blocks
- The Codex Agent Loop Deep Dive — how Codex implements the pipeline
- Claude Code Open Source Architecture — Claude’s take on the same loop
- Codex CLI vs Claude Code Architecture — head-to-head comparison
- Cross-Platform Agent Portability — AGENTS.md and CLAUDE.md
- Codex CLI Competitive Position, April 2026 — market landscape
- The Codex App Server: A Complete Guide — the protocol beneath the pipeline
- Cross-Platform Agent Friction — what still does not port
- What Microservices Taught Us About Building AI Coding Agents — the architectural parallels in depth
Footnotes
-
Nadeem et al., “Inside the Scaffold: A Source-Code Taxonomy of Coding Agent Architectures,” arXiv, April 2026. https://arxiv.org/html/2604.03515 ↩ ↩2 ↩3
-
Anthropic, “How the Agent Loop Works — Claude Code Agent SDK,” April 2026. https://code.claude.com/docs/en/agent-sdk/agent-loop ↩
-
OpenAI, “App Server Protocol — Thread, Turn, Item Primitives,” Codex Developer Documentation. https://github.com/openai/codex/blob/main/codex-rs/app-server/README.md ↩
-
MCP adoption statistics: 97 million monthly SDK downloads as of April 2026. https://mcpmanager.ai/blog/mcp-adoption-statistics/ ↩
-
Anthropic donated MCP to the Agentic AI Foundation (AAIF) under the Linux Foundation, December 2025. https://dev.to/pockit_tools/mcp-vs-a2a-the-complete-guide-to-ai-agent-protocols-in-2026-30li ↩
-
Tessl, “The Rise of AGENTS.md: An Open Standard and Single Source of Truth for AI Coding Agents,” March 2026. https://tessl.io/blog/the-rise-of-agents-md-an-open-standard-and-single-source-of-truth-for-ai-coding-agents/ ↩
-
Crosley, “Codex CLI vs Claude Code in 2026: Architecture Deep Dive,” April 2026. https://blakecrosley.com/blog/codex-vs-claude-code-2026 ↩
-
OpenAI, “Codex CLI Approval Modes — suggest, auto-edit, full-auto,” Codex Documentation. https://developers.openai.com/codex/concepts/sandboxing ↩
-
Tompkins et al., “Building AI Coding Agents for the Terminal,” arXiv, March 2026. https://arxiv.org/html/2603.05344v1 ↩
-
Mason, “AI Coding Agents in 2026: Coherence Through Orchestration, Not Autonomy,” January 2026. https://mikemason.ca/writing/ai-coding-agents-jan-2026/ ↩
-
Beck, K., interviewed by Orosz, G., “TDD, AI Agents, and Coding with Kent Beck,” The Pragmatic Engineer, April 2026. https://newsletter.pragmaticengineer.com/p/tdd-ai-agents-and-coding-with-kent ↩
-
LangChain, “Open SWE: An Open-Source Framework for Internal Coding Agents,” April 2026. Built by studying production agents at Stripe, Ramp, and Coinbase. https://www.langchain.com/blog/open-swe-an-open-source-framework-for-internal-coding-agents/ ↩
-
Open SWE architecture: pluggable sandbox providers, curated toolsets (~15 tools), subagent delegation via
tasktool, middleware hooks for safety nets. https://github.com/langchain-ai/open-swe ↩ -
Osmani, A., “Agent Skills — Engineering discipline for AI coding agents,” April 2026. 19 skills + 7 commands encoding Google engineering culture, working across Claude Code, Cursor, and Gemini CLI. 10,000+ GitHub stars. https://www.linkedin.com/posts/addyosmani_ai-softwareengineering-programming-activity-7448255964102950912-vScT ↩
-
The New Stack, “5 Key Trends Shaping Agentic Development in 2026.” https://thenewstack.io/5-key-trends-shaping-agentic-development-in-2026/ ↩
-
Cross-agent interoperability tools: ruler (2.6K stars), cc-switch (35.3K stars) for config sync; mimir and CASS for session sharing across agents. ↩