The Codex CLI Model Landscape in May 2026: A Practitioner's Routing Guide
The Codex CLI Model Landscape in May 2026: A Practitioner’s Routing Guide
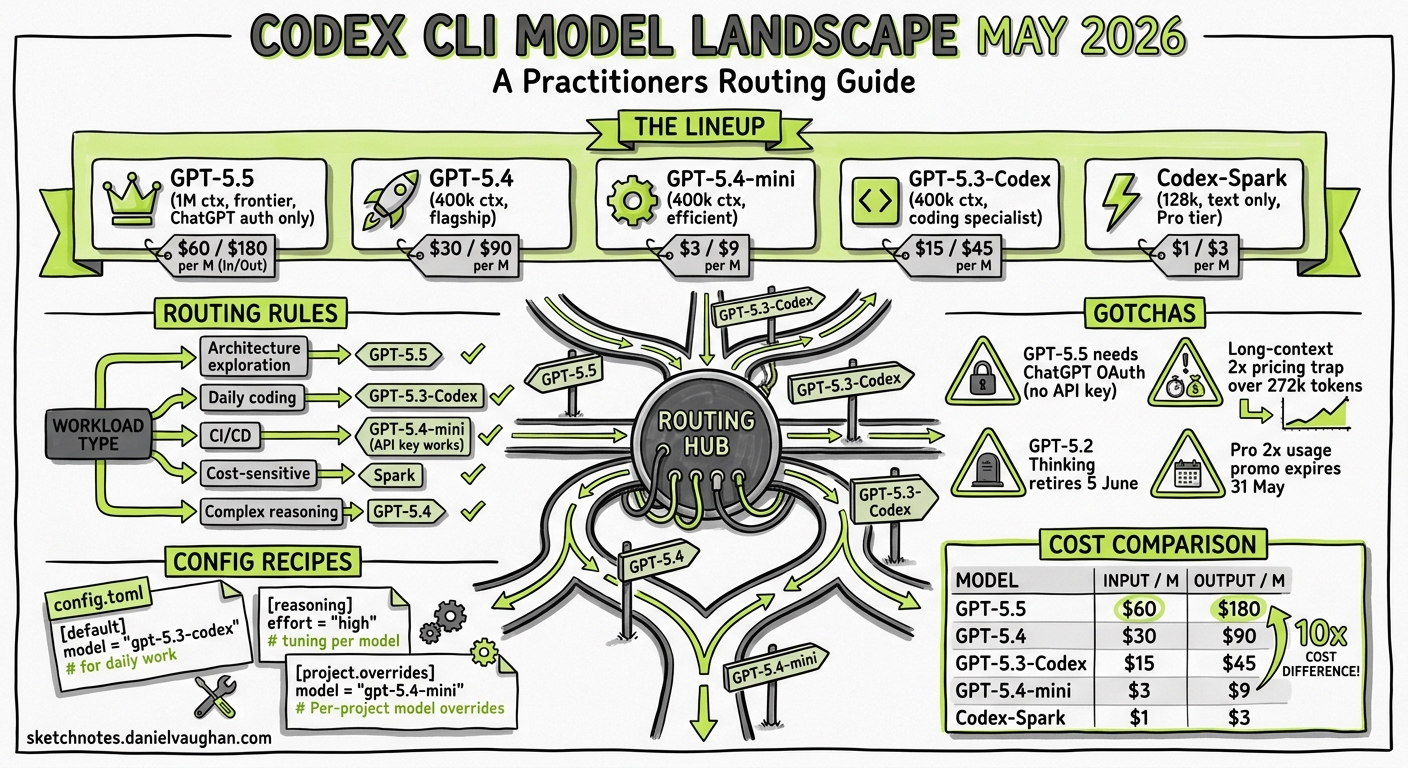
Three months ago, Codex CLI users chose between GPT-5-Codex and its Spark variant. Today the model picker lists five production options — six if you count GPT-5.5 Pro — each with different context windows, reasoning tiers, authentication requirements, and per-token economics. GPT-5.2 Thinking retires on 5 June1, and the promotional 2× usage on the Pro $100 tier expires on 31 May2. If you have not reviewed your config.toml model settings recently, now is the time.
This article maps the full Codex CLI model landscape as of May 2026, provides concrete routing rules, and offers ready-to-use configuration recipes for common workflows.
The Current Lineup
graph LR
subgraph Frontier
A["GPT-5.5<br/>1M ctx · $5/$30<br/>ChatGPT auth only"]
B["GPT-5.5 Pro<br/>1M ctx · $30/$180<br/>Pro $200 only"]
end
subgraph Flagship
C["GPT-5.4<br/>400k ctx · $2.50/$15<br/>API + ChatGPT"]
end
subgraph Efficient
D["GPT-5.4-mini<br/>400k ctx · $0.75/$4.50<br/>API + ChatGPT"]
end
subgraph Coding-Specialist
E["GPT-5.3-Codex<br/>400k ctx · $1.75/$14<br/>API + ChatGPT"]
F["GPT-5.3-Codex-Spark<br/>128k ctx · text only<br/>Pro $200 only"]
end
A --> C
C --> D
C --> E
E --> F
GPT-5.5
OpenAI’s newest frontier model, released 24 April 20263. It supports a 1,050,000-token context window, image input, and every Codex tool surface — computer use, hosted shell, apply patch, MCP, web search, and skills3. Reasoning effort defaults to medium and supports low, medium, high, and xhigh.
Critical limitation: GPT-5.5 requires ChatGPT OAuth sign-in. It is not available with API-key authentication4. This means CI/CD pipelines using OPENAI_API_KEY cannot target it. If your workflow relies on codex exec with an API key, GPT-5.5 is off the table.
Long-context pricing trap: Prompts exceeding 272,000 input tokens trigger 2× input and 1.5× output pricing for the entire session5. A 300k-token session that would cost $1.50 at base rates actually costs $3.00 in input alone.
GPT-5.4
The flagship general-purpose model, combining strong coding with enhanced reasoning4. GPT-5.4 subsumes the capabilities of GPT-5.3-Codex — OpenAI describes it as “the first mainline reasoning model to incorporate the frontier coding capabilities from GPT-5.3-Codex”6. It supports 400,000 tokens of context and the same reasoning effort levels as GPT-5.5.
GPT-5.4 is 47% more token-efficient than GPT-5.3-Codex on complex tasks7, meaning its higher per-token cost ($2.50 vs $1.75 per million input tokens) often translates to lower per-task cost. It also wins 4 out of 6 major benchmarks against GPT-5.3-Codex, including SWE-Bench Pro and OSWorld7.
Key advantage over GPT-5.5: Full API-key support, making it the strongest model available for headless automation.
GPT-5.4-mini
The cost-optimised workhorse at $0.75/$4.50 per million tokens — roughly 6× cheaper than GPT-5.48. It shares the 400k context window and supports reasoning tokens, but trades peak capability for throughput and latency. Ideal for subagent delegation, fast triage, and high-volume batch work.
GPT-5.3-Codex
The purpose-built coding specialist, released 5 February 20269. Despite its age, it still holds a 2.2-point lead on Terminal-Bench 2.0 (77.3% vs 75.1% for GPT-5.4)7 — the benchmark most closely aligned with CLI-centric workflows. At $1.75/$14.00 per million tokens10, it is 30% cheaper than GPT-5.4 on input tokens.
GPT-5.3-Codex scored 56.8% on SWE-Bench Pro Public and approximately 80.0% on SWE-Bench Verified9. Its cybersecurity capabilities were classified “High” under OpenAI’s Preparedness Framework9.
Where it still wins: Pure terminal coding at high volume where per-token cost matters more than per-task efficiency. At 61.9 tokens per second throughput, it remains the fastest frontier-tier option for streaming output in the TUI7.
GPT-5.3-Codex-Spark
A research preview optimised for near-instant iteration11. Text-only, 128k context window, available exclusively to ChatGPT Pro ($200) subscribers. It cannot process images, run computer use, or work through the API. Think of it as a prototype for low-latency pairing — useful for rapid exploratory coding but not for production pipelines.
Routing Decision Tree
The following heuristic covers the majority of Codex CLI use cases:
flowchart TD
A[Start: Choose model] --> B{CI/CD or headless?}
B -->|Yes| C{Complex reasoning<br/>needed?}
C -->|Yes| D["GPT-5.4<br/>flagship, API-key compatible"]
C -->|No| E{Cost sensitive?}
E -->|Yes| F["GPT-5.4-mini<br/>6x cheaper"]
E -->|No| D
B -->|No, interactive| G{Task type?}
G -->|Research, long-context,<br/>computer use| H["GPT-5.5<br/>if available"]
G -->|Terminal-heavy coding| I{Budget constraint?}
I -->|Yes| J["GPT-5.3-Codex<br/>30% cheaper input"]
I -->|No| D
G -->|Rapid prototyping| K{Pro $200 subscriber?}
K -->|Yes| L["GPT-5.3-Codex-Spark<br/>lowest latency"]
K -->|No| D
Rules of Thumb
- Default to GPT-5.4 unless you have a specific reason not to. It is the most broadly capable model with full API support.
- Use GPT-5.5 for research-heavy or multimodal sessions where you need the million-token context window and are signed in via ChatGPT.
- Use GPT-5.3-Codex for high-volume terminal coding where throughput and per-token cost matter more than per-task efficiency.
- Use GPT-5.4-mini for subagents and batch work. Its 6× cost reduction makes it the natural choice for delegated tasks that do not require frontier reasoning.
- Avoid GPT-5.5 in CI/CD. The ChatGPT-only authentication requirement is a hard blocker for non-interactive pipelines.
Configuration Recipes
Daily Driver (Interactive)
# ~/.codex/config.toml
model = "gpt-5.4"
model_reasoning_effort = "medium"
[profile.deep]
model = "gpt-5.5"
model_reasoning_effort = "high"
Switch to the deep profile for long research sessions:
codex --profile deep
CI/CD Pipeline
# .codex/config.toml (repo-level)
model = "gpt-5.4"
model_reasoning_effort = "low"
approval_mode = "never"
sandbox = "read-only"
For cost-sensitive batch runs:
codex exec --model gpt-5.4-mini --sandbox read-only \
"Review the diff and produce a JSON summary" \
--output-schema review-schema.json
Subagent Delegation
# .codex/config.toml
model = "gpt-5.4"
[agents]
model = "gpt-5.4-mini"
max_threads = 6
max_depth = 1
This routes the primary agent through GPT-5.4 whilst delegating subagent work to GPT-5.4-mini — a common pattern that reduces cost by 60–70% on parallelised tasks without sacrificing orchestration quality.
Terminal-Heavy Coding on a Budget
# ~/.codex/config.toml
model = "gpt-5.3-codex"
model_reasoning_effort = "high"
This configuration maximises coding capability per token spent. The high reasoning effort on GPT-5.3-Codex still costs less per million tokens than medium effort on GPT-5.4.
Cost Comparison Matrix
| Model | Input ($/1M) | Cached ($/1M) | Output ($/1M) | Context | API Key | Best For |
|---|---|---|---|---|---|---|
| GPT-5.5 | $5.00 | $0.50 | $30.00 | 1.05M | No | Research, computer use |
| GPT-5.5 Pro | $30.00 | — | $180.00 | 1.05M | No | Maximum capability |
| GPT-5.4 | $2.50 | $0.25 | $15.00 | 400k | Yes | General-purpose default |
| GPT-5.4-mini | $0.75 | $0.075 | $4.50 | 400k | Yes | Subagents, batch |
| GPT-5.3-Codex | $1.75 | $0.175 | $14.00 | 400k | Yes | High-volume terminal coding |
| Codex-Spark | Included | — | Included | 128k | No | Rapid pairing (Pro $200) |
All API prices are per million tokens5810. Codex-Spark is subscription-only with separate rate limits11.
The GPT-5.2 Retirement Clock
GPT-5.2 Thinking retires on 5 June 20261. If your config.toml still references gpt-5.2-thinking or any GPT-5.2 variant, you have roughly one month to migrate. The recommended path is straightforward:
# Before (deprecated)
model = "gpt-5.2-thinking"
# After
model = "gpt-5.4"
GPT-5.4 is described by OpenAI as “strictly better for all use cases” compared to GPT-5.2 Thinking6. The only exception is production code tightly coupled to the older API response format — test your pipelines before the deadline.
Authentication Gotchas
The authentication split between ChatGPT OAuth and API keys creates practical friction:
flowchart LR
subgraph "ChatGPT OAuth"
A[GPT-5.5]
B[GPT-5.5 Pro]
C[Codex-Spark]
end
subgraph "API Key OR OAuth"
D[GPT-5.4]
E[GPT-5.4-mini]
F[GPT-5.3-Codex]
end
subgraph "Use Cases"
G[Interactive TUI]
H[codex exec / CI]
I[Subagent delegation]
end
A --> G
D --> G
D --> H
E --> H
E --> I
F --> H
Practical consequence: Teams running mixed workflows — interactive development plus automated CI — should standardise on GPT-5.4 as the common denominator. Developers who want GPT-5.5 for interactive sessions can override locally:
# ~/.codex/config.toml (personal)
model = "gpt-5.5"
# .codex/config.toml (repo, committed)
model = "gpt-5.4"
The repo-level configuration ensures CI/CD pipelines always target an API-key-compatible model, whilst individual developers can use GPT-5.5 when signed in through ChatGPT.
The Promotional Window
Until 31 May 2026, Pro $100 subscribers receive 2× their standard Codex usage — effectively 10× Plus limits instead of the usual 5×2. This makes the current month an unusually cost-effective window for heavy interactive work with GPT-5.5 or GPT-5.4. If you have been deferring large refactoring sessions or codebase-wide migrations, the economics favour doing them now.
After 31 May, Pro $100 reverts to 5× Plus limits. Pro $200 retains its 20× multiplier unchanged.
Looking Ahead
The trend is clear: OpenAI is consolidating model lines. GPT-5.4 absorbed GPT-5.3-Codex’s coding capabilities. GPT-5.5 pushed the frontier further. The specialist models (GPT-5.3-Codex, Codex-Spark) remain available but their long-term trajectory points towards absorption into future general-purpose releases.
For now, the pragmatic approach is a three-model strategy:
- GPT-5.4 as the default for everything
- GPT-5.4-mini for cost-sensitive delegation
- GPT-5.5 for interactive sessions requiring maximum capability or long context
This covers CI/CD, interactive development, and subagent orchestration without requiring constant model-switching or authentication juggling.
Citations
-
OpenAI, “GPT-5.4 vs GPT-5.2: What Changed & Should You Upgrade?”, NxCode, 2026. https://www.nxcode.io/resources/news/gpt-5-4-vs-gpt-5-2-comparison-upgrade-guide-2026 ↩ ↩2
-
OpenAI, “Codex Pricing”, OpenAI Developers, 2026. https://developers.openai.com/codex/pricing ↩ ↩2
-
OpenAI, “Introducing GPT-5.5”, OpenAI Blog, April 2026. https://openai.com/index/introducing-gpt-5-5/ ↩ ↩2
-
OpenAI, “Codex Models”, OpenAI Developers, 2026. https://developers.openai.com/codex/models ↩ ↩2
-
OpenAI, “API Pricing”, OpenAI Developers, 2026. https://developers.openai.com/api/docs/pricing ↩ ↩2
-
OpenAI, “Introducing GPT-5.4”, OpenAI Blog, March 2026. https://openai.com/index/introducing-gpt-5-4/ ↩ ↩2
-
NxCode, “GPT-5.4 vs GPT-5.3 Codex: Should Developers Upgrade?”, 2026. https://www.nxcode.io/resources/news/gpt-5-4-vs-gpt-5-3-codex-upgrade-comparison-2026 ↩ ↩2 ↩3 ↩4
-
OpenAI, “GPT-5.4 mini Model”, OpenAI API Docs, 2026. https://developers.openai.com/api/docs/models/gpt-5.4-mini ↩ ↩2
-
OpenAI, “GPT-5.3-Codex System Card”, February 2026. https://cdn.openai.com/pdf/23eca107-a9b1-4d2c-b156-7deb4fbc697c/GPT-5-3-Codex-System-Card-02.pdf ↩ ↩2 ↩3
-
OpenAI, “GPT-5.3-Codex Model”, OpenAI API Docs, 2026. https://developers.openai.com/api/docs/models/gpt-5.3-codex ↩ ↩2
-
OpenAI, “Introducing GPT-5.3-Codex-Spark”, OpenAI Blog, 2026. https://openai.com/index/introducing-gpt-5-3-codex-spark/ ↩ ↩2