Codex CLI Model Routing in May 2026: GPT-5.5, GPT-5.4, Codex-Spark, and When to Use Each
Codex CLI Model Routing in May 2026: GPT-5.5, GPT-5.4, Codex-Spark, and When to Use Each
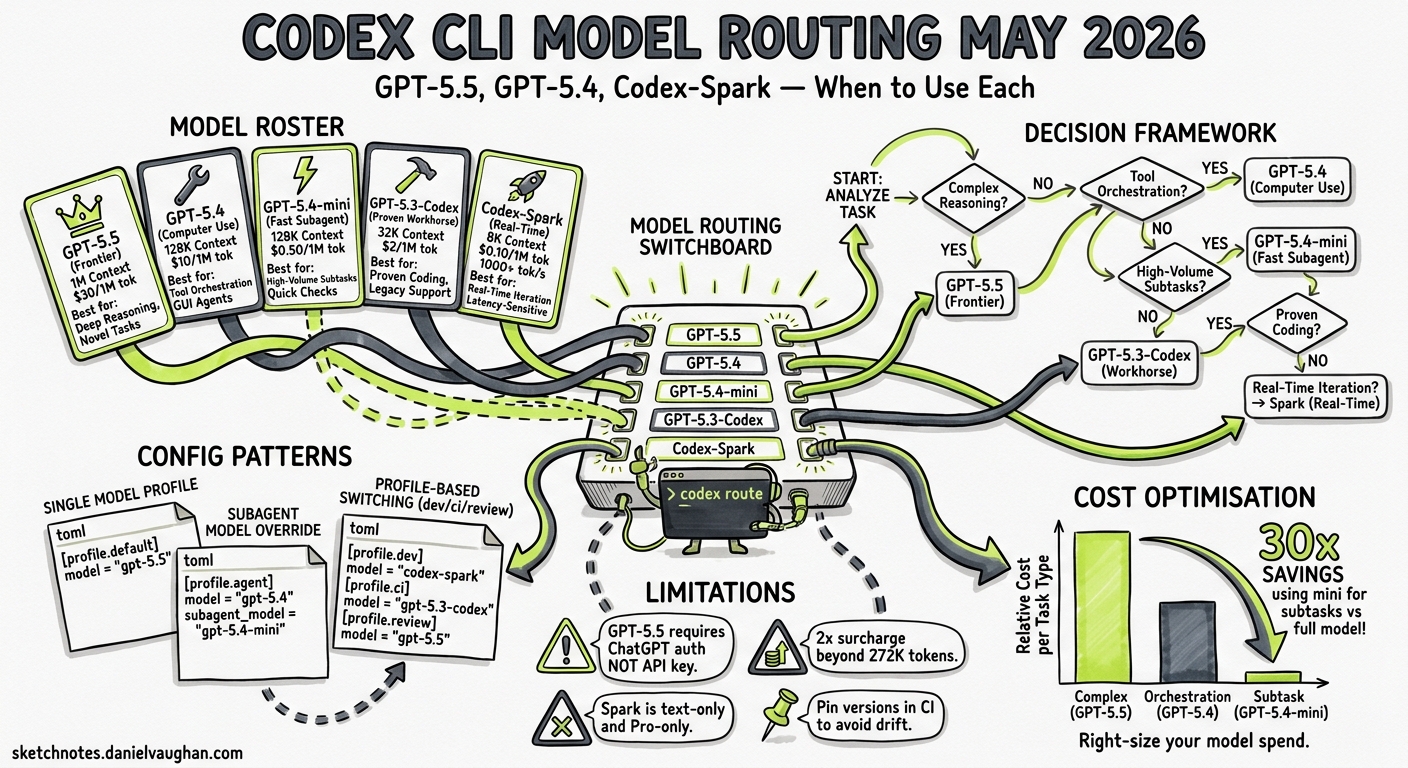
The model lineup available to Codex CLI developers has changed materially since March 2026. GPT-5.5 arrived in late April as the new frontier1, GPT-5.4 brought native computer-use and stronger tool orchestration2, GPT-5.4-mini carved out a niche as the purpose-built subagent model3, and GPT-5.3-Codex-Spark continues to offer sub-second latency for real-time iteration4. Choosing the right model for each task — and configuring Codex CLI to route automatically — is now a first-class engineering decision. This article maps the current roster, benchmarks, pricing, and practical configuration patterns for May 2026.
The May 2026 Model Roster
Five models are currently available in Codex CLI, documented at the official models page5. Their capabilities, context windows, and price points differ enough that no single model is optimal for every workflow.
| Model | Context Window | Input / Cached / Output (per 1M tokens) | SWE-Bench Pro | Terminal-Bench 2.0 | Key Strength |
|---|---|---|---|---|---|
gpt-5.5 |
1M (922K in + 128K out) | $5.00 / $0.50 / $30.00 | — | 82.7% | Frontier reasoning, research, long-horizon |
gpt-5.4 |
1M (272K standard) | $2.50 / $0.25 / $15.00 | 57.7% | — | Tool use, computer use, professional tasks |
gpt-5.4-mini |
400K | $0.75 / $0.075 / $4.50 | 54.4% | 60.0% | Fast subagents, high-volume tasks |
gpt-5.3-codex |
400K | $1.75 / $0.175 / $14.00 | 56.8% | 77.3% | Proven coding workhorse |
gpt-5.3-codex-spark |
128K | Research preview (Pro only) | — | — | Real-time iteration at 1,000+ tok/s |
Note: GPT-5.5 applies a 2x input surcharge beyond 272K tokens1. GPT-5.4 applies the same surcharge beyond its 272K standard window6. GPT-5.3-Codex-Spark is text-only and available exclusively to ChatGPT Pro subscribers4.
Model Profiles in Detail
GPT-5.5: The New Frontier
Released 23 April 2026, GPT-5.5 is OpenAI’s most capable model across reasoning, coding, and agentic tasks1. It holds state-of-the-art results on Terminal-Bench 2.0 (82.7%), OSWorld-Verified (78.7%), and FrontierMath Tier 4 (35.4%)1. In Codex, the official recommendation is to “start with gpt-5.5 when it appears in your model picker”5.
GPT-5.5 is available when authenticating with a ChatGPT account. It is not available via API-key authentication at this time5.
Best for: Complex refactoring across large codebases, multi-step research tasks, long-horizon goal workflows, and sessions requiring deep reasoning.
GPT-5.4: The Professional Workhorse
GPT-5.4 launched 5 March 2026 as the first mainline model to incorporate GPT-5.3-Codex’s frontier coding capabilities directly2. Its distinguishing feature is native computer-use support — the first general-purpose model with state-of-the-art desktop automation, scoring 75% on OSWorld (surpassing the 72.4% human expert baseline)2.
Best for: Tasks involving tool orchestration, browser interaction, desktop automation, professional document workflows, and coding tasks that benefit from strong tool-calling capabilities.
GPT-5.4-mini: The Subagent Specialist
Pushed to the API on 17 March 2026, GPT-5.4-mini was explicitly designed for the subagent era3. It scores 54.4% on SWE-Bench Pro whilst being twice as fast as its predecessor and costing roughly 30% of the GPT-5.4 quota in Codex3. For most narrowly-scoped subtasks — searching a codebase, reviewing a single file, processing supporting documents — the quality difference from the full model is negligible.
Best for: Subagent delegation, parallel file searches, code review of individual files, batch processing, and any high-volume task where latency and cost matter more than peak reasoning.
GPT-5.3-Codex: The Proven Specialist
GPT-5.3-Codex (released 5 February 2026) remains a strong choice for pure coding tasks7. At 56.8% on SWE-Bench Pro and 77.3% on Terminal-Bench 2.0, it trades breadth for coding depth — and at $1.75/$14.00 per million tokens, it undercuts GPT-5.4 on cost whilst maintaining competitive coding benchmarks7.
Best for: Pure software engineering tasks where tool-use and computer-use are unnecessary, CI/CD automation via codex exec, and cost-sensitive pipelines.
Deprecation note: GPT-5.3-Codex is being phased out in favour of newer models8. Plan migration to GPT-5.4 or GPT-5.5 for new projects.
GPT-5.3-Codex-Spark: Real-Time Iteration
Codex-Spark is the product of OpenAI’s partnership with Cerebras, running on the Wafer-Scale Engine 3 at over 1,000 tokens per second4. With a 128K text-only context window and research-preview status, it trades capability for raw speed.
Best for: Tight edit-test loops, rapid prototyping, interactive TUI sessions where latency frustration outweighs reasoning depth, and exploratory coding.
Configuration Patterns
Setting a Default Model
In ~/.codex/config.toml:
model = "gpt-5.5"
Or override per session:
codex --model gpt-5.4 "Refactor the auth module"
Named Profiles for Model Routing
Codex v0.128 expanded profile support with built-in defaults9. Define workflow-specific profiles that select models automatically:
[profile.deep-work]
model = "gpt-5.5"
[profile.fast-iterate]
model = "gpt-5.3-codex-spark"
[profile.ci-pipeline]
model = "gpt-5.4-mini"
Activate a profile from the command line:
codex --profile deep-work "Analyse this codebase and propose an architecture migration"
codex --profile fast-iterate "Fix the failing test in auth.test.ts"
codex --profile ci-pipeline "Summarise the open bugs in JSON format"
Subagent Model Configuration
Configure subagents to use cheaper, faster models whilst the orchestrator retains the frontier model10:
model = "gpt-5.5"
[agents]
model = "gpt-5.4-mini"
This pattern routes the primary session through GPT-5.5 for planning and coordination, whilst delegated subtasks run on GPT-5.4-mini at roughly one-sixth the cost per output token.
Mid-Session Model Switching
Use the /model slash command to switch models without restarting:
/model gpt-5.3-codex-spark
This is useful when transitioning from a planning phase (where deeper reasoning helps) to a rapid implementation phase (where speed matters more).
The Decision Framework
flowchart TD
START["New Codex Task"] --> Q1{"Complex reasoning\nor multi-step\nresearch?"}
Q1 -->|Yes| GPT55["gpt-5.5\n$5 / $30 per 1M"]
Q1 -->|No| Q2{"Needs tool use,\nbrowser, or\ncomputer use?"}
Q2 -->|Yes| GPT54["gpt-5.4\n$2.50 / $15 per 1M"]
Q2 -->|No| Q3{"Subagent or\nhigh-volume\nbatch task?"}
Q3 -->|Yes| MINI["gpt-5.4-mini\n$0.75 / $4.50 per 1M"]
Q3 -->|No| Q4{"Need sub-second\nlatency for\ntight loops?"}
Q4 -->|Yes| SPARK["gpt-5.3-codex-spark\nPro only, 128K context"]
Q4 -->|No| Q5{"Cost-sensitive\npure coding\npipeline?"}
Q5 -->|Yes| CODEX["gpt-5.3-codex\n$1.75 / $14 per 1M"]
Q5 -->|No| GPT54
Cost Comparison: A Practical Example
Consider a typical 30-minute coding session consuming approximately 50K input tokens and 20K output tokens (accounting for prompt caching hitting roughly 60% of input):
| Model | Input Cost | Cached Savings | Output Cost | Total |
|---|---|---|---|---|
gpt-5.5 |
$0.25 | -$0.135 | $0.60 | $0.715 |
gpt-5.4 |
$0.125 | -$0.0675 | $0.30 | $0.358 |
gpt-5.4-mini |
$0.0375 | -$0.020 | $0.09 | $0.107 |
gpt-5.3-codex |
$0.0875 | -$0.047 | $0.28 | $0.320 |
Over a team of ten developers each running five sessions daily, the difference between routing everything through GPT-5.5 and routing routine work through GPT-5.4-mini adds up to roughly $150/day — or $3,000/month — in savings.
The Prompt Caching Advantage
All models in the roster support prompt caching at 90% input cost reduction11. This has significant routing implications:
- Long sessions benefit disproportionately from caching, making GPT-5.5’s higher base price less painful as the session progresses
- Repeated
codex execinvocations with similar prompts (CI pipelines, batch operations) can achieve 60-80% cache hit rates - Subagent spawns that share the parent session’s context inherit cached prefixes
Configure caching behaviour in config.toml:
[model]
prompt_caching = true
Authentication and Model Availability
A critical routing consideration: model availability depends on your authentication method5.
| Authentication | GPT-5.5 | GPT-5.4 | GPT-5.4-mini | GPT-5.3-Codex | Spark |
|---|---|---|---|---|---|
| ChatGPT (Plus/Pro) | Yes | Yes | Yes | Yes | Pro only |
| API Key | No | Yes | Yes | Yes | No |
For CI/CD pipelines using API-key authentication, GPT-5.4 is the ceiling. Teams that need GPT-5.5 in automated workflows should evaluate the Codex SDK with ChatGPT authentication or the codex-action GitHub Action12.
Deprecation Timeline
GPT-5.3-Codex follows a standard three-month deprecation window from the point a successor reaches general availability8. With GPT-5.4 having launched in March 2026, expect GPT-5.3-Codex to reach end-of-life by June 2026. The chat-latest dynamic pointer (currently resolving to GPT-5.5 Instant) provides an alternative for teams that want automatic model upgrades without configuration changes13.
Recommendations
- Default to GPT-5.5 for interactive TUI sessions where you authenticate via ChatGPT — it is the recommended starting point5
- Use GPT-5.4 as the CI/CD workhorse — it is the most capable model available via API key and handles tool-calling workflows well
- Route subagents to GPT-5.4-mini — the 30% quota cost and 2x speed make it the clear choice for delegated subtasks3
- Reserve Codex-Spark for tight iteration loops — when latency is the bottleneck, nothing else comes close at 1,000+ tokens per second
- Migrate off GPT-5.3-Codex for new projects — it remains competitive on pure coding benchmarks but faces deprecation
- Enable prompt caching everywhere — the 90% input cost reduction compounds across sessions and is model-agnostic