Qwen3.6-35B-A3B: The Local Model That Changes the Agentic Cost Equation
Qwen3.6-35B-A3B: The Local Model That Changes the Agentic Cost Equation
Source: https://huggingface.co/Qwen/Qwen3.6-35B-A3B Author: Qwen Team (Alibaba Cloud) Date saved: 2026-04-16 Content age: Current as of April 2026
Summary
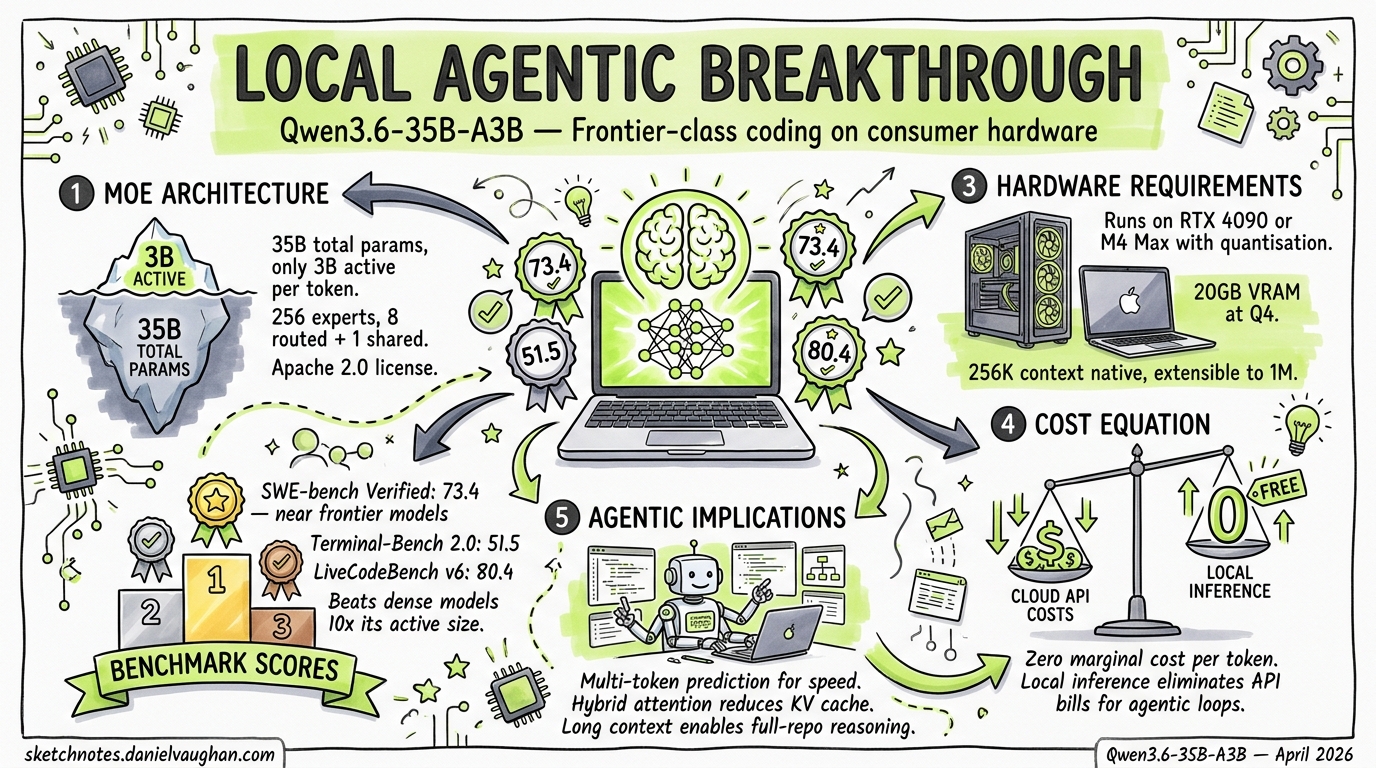
Qwen3.6-35B-A3B is a Mixture-of-Experts model with 35 billion total parameters but only 3 billion active per token. It scores 73.4 on SWE-bench Verified — within striking distance of frontier API models — while running on consumer hardware. This fundamentally changes the local model argument for agentic engineering: it is no longer about “good enough for simple tasks” but “frontier-class performance at zero marginal cost.”
Key Points
Architecture
- Type: Mixture-of-Experts (MoE) with vision encoder (multimodal)
- Total parameters: 35B
- Active parameters per token: 3B (8.6% activation ratio)
- Expert configuration: 256 total experts, 8 routed + 1 shared activated per token
- Hybrid attention: 3 layers of Gated DeltaNet (linear attention) per 1 layer of standard Gated Attention — reduces KV cache pressure
- Context window: 256K native, extensible to ~1M via YaRN RoPE scaling
- Multi-Token Prediction (MTP): Trained for speculative decoding — significant inference speedup
- License: Apache 2.0
Coding Agent Benchmarks
The headline numbers are remarkable for a model that runs locally:
| Benchmark | Qwen3.6-35B-A3B | Qwen3.5-27B (dense) | Gemma4-31B (dense) | Gemma4-26B-A4B (MoE) |
|---|---|---|---|---|
| SWE-bench Verified | 73.4 | 75.0 | 52.0 | 17.4 |
| SWE-bench Multilingual | 67.2 | 69.3 | 51.7 | 17.3 |
| Terminal-Bench 2.0 | 51.5 | 41.6 | 42.9 | 34.2 |
| LiveCodeBench v6 | 80.4 | 80.7 | 80.0 | 77.1 |
| MCPMark | 37.0 | 36.3 | 18.1 | 14.2 |
| Tool Decathlon | 26.9 | 31.5 | 21.2 | 12.0 |
| NL2Repo | 29.4 | 27.3 | 15.5 | 11.6 |
Key observations:
- 73.4 SWE-bench Verified from 3B active params — nearly matches its own dense 27B sibling (75.0) while using ~10x fewer active parameters
- 51.5 Terminal-Bench 2.0 — actually EXCEEDS the dense 27B model (41.6), suggesting MoE routing helps for terminal/CLI tasks
- Destroys Gemma4 on coding — 73.4 vs 52.0 (dense) and 73.4 vs 17.4 (MoE) on SWE-bench. The Gemma4-26B-A4B MoE comparison is particularly stark: similar active parameter count, vastly different coding performance
- MCPMark 37.0 — double Gemma4-31B’s 18.1, indicating strong tool-use and MCP integration capability
Agentic Capabilities
- Tool calling: Built-in, with dedicated parser for SGLang (
--tool-call-parser qwen3_coder) and vLLM - MCP support: Benchmarked on MCPMark and MCP-Atlas; Qwen-Agent integration supports MCP configuration files
- Qwen Code: Dedicated open-source terminal coding agent optimised for Qwen models — similar to Claude Code but runs locally
- Thinking preservation: Retains reasoning context across multi-turn agent conversations, reducing redundant inference
Hardware Requirements
The 3B active parameter count is the key enabler for consumer hardware:
| Quantization | Model Size | Min VRAM/RAM | Suitable Hardware |
|---|---|---|---|
| Q4_K_M (GGUF) | ~18-20 GB | 24 GB | M4 Pro 24GB, RTX 4090 |
| Q5_K_M (GGUF) | ~22-24 GB | 32 GB | M5 Pro 36GB, 2x RTX 4080 |
| FP8 | ~35 GB | 48 GB | M5 Pro 48GB, A6000 |
| FP16 | ~70 GB | 80+ GB | Multi-GPU or M5 Max 96GB |
With Q4 quantization on an M5 Pro Mac (36GB unified memory), the model fits comfortably with room for a 128K+ context window — sufficient for serious agentic coding sessions.
What This Means for Agentic Engineering
The cost equation has flipped. When the TDAD paper1 evaluated Qwen3-Coder 30B on consumer hardware and found that structural test maps reduced regressions by 70%, the implicit caveat was “but frontier models will do better.” Qwen3.6-35B-A3B closes that gap dramatically: 73.4 SWE-bench Verified is within 10% of Claude Sonnet 4.6’s scores, and Terminal-Bench 2.0 at 51.5 suggests the model is particularly strong at the CLI-based agentic workflows that Codex CLI and similar tools depend on.
The hybrid stack gets real. Article 11 in the premium series argues for routing simple tasks to local models and complex tasks to API models. Qwen3.6 pushes the boundary of “simple” dramatically upward — a model that scores 73.4 on SWE-bench can handle most implementation tasks, reserving API calls for only the most complex architectural reasoning.
The subsidy trap has an exit. If Claude Code Max or Codex Pro pricing changes overnight (as happened with OpenClaw), teams running Qwen3.6 locally have a genuine fallback that maintains most of their productivity. The $2,199 M5 Pro Mac pays for itself in under two months of avoided API costs at heavy usage rates.
Notable Commands / Code
# Run with SGLang (recommended for tool calling)
python -m sglang.launch_server \
--model-path Qwen/Qwen3.6-35B-A3B \
--tool-call-parser qwen3_coder \
--tp-size 2 \
--context-length 262144
# Run with vLLM
vllm serve Qwen/Qwen3.6-35B-A3B \
--tool-call-parser qwen3_coder \
--tensor-parallel-size 2 \
--max-model-len 262144
# Run with ollama (GGUF quantized)
ollama run qwen3.6-coder:35b-a3b-q4
# Codex CLI config for local Qwen3.6
# In ~/.codex/config.toml:
# [profiles.local]
# model = "qwen3.6-35b-a3b"
# provider = "openai-compatible"
# api_base = "http://localhost:30000/v1"
Comparison to Gemma 4 (Previous Local Model Benchmark)
The Gemma 4 articles in this repo23 established the local model case with Gemma4-27B scoring competitively on general tasks. Qwen3.6 represents a generational leap for coding specifically:
| Metric | Gemma4-31B | Gemma4-26B-A4B | Qwen3.6-35B-A3B | Delta vs best Gemma |
|---|---|---|---|---|
| SWE-bench Verified | 52.0 | 17.4 | 73.4 | +41% |
| Terminal-Bench 2.0 | 42.9 | 34.2 | 51.5 | +20% |
| MCPMark | 18.1 | 14.2 | 37.0 | +104% |
| Active params | 31B | 4B | 3B | Fewer |
Gemma 4 remains strong for general-purpose reasoning and multimodal tasks, but for agentic coding workflows specifically, Qwen3.6 is now the clear local model leader.
Personal Notes
This model is a milestone for the “local model safety net” thesis in premium article 11. The argument was always: “local models handle simple tasks, API models handle complex ones.” Qwen3.6 blurs that line — 73.4 SWE-bench is not “simple task” territory. It is production-grade agentic coding.
The implications for the book’s chapter 15 (context windows) and chapter 31 (harness engineering) are also significant: a 256K native context with 3B active parameters means local agentic sessions can run for hours without compaction, at zero marginal cost.
The TDAD study’s use of Qwen3-Coder 30B now looks prescient rather than limiting — the successor model validates that structural testing approaches work even better as the underlying models improve.
Citations
-
Alonso, P., Yovine, S., Braberman, V. A. (2026). “TDAD: Test-Driven Agentic Development.” arXiv:2603.17973v2. Used Qwen3-Coder 30B and Qwen3.5-35B-A3B for evaluation. ↩
-
“Gemma 4 as a Local Model for Codex CLI” — codex-resources, 10 April 2026. ↩
-
“Gemma 4: Codex CLI vs Claude Code Local Model Comparison” — codex-resources, 12 April 2026. ↩